Blog Entries all / by tag / by year / popular
Cave of Forgotten Dreams

Who is he that hideth counsel without knowledge? therefore have I uttered that I understood not; things too wonderful for me, which I knew not.
"Hold on a sec-". My new boss' now-familiar MacOS desktop appeared in the video call, browser with Claude open, dominating the screen. I watched as he copied the transcript of our call up to that point (he records transcripts of every call in order to feed the text into AI), and began a new chat with the prompt: "Say where Charlie's right, and where he's wrong. Say where I'm right and where I'm wrong." He pasted the transcript and hit enter. I consulted my avatar in the lower-right. We both waited in silence while Claude thought. We were 45 minutes into a call about product roadmap and a possible customer announcement before this interruption. Soon the cursor started skipping along as words began filling the screen. Then, we read aloud through the findings one-by-one. Claude had helpfully given us a bulleted list to work through, an even number of findings for each of us. I felt called-upon to gallantly agree with Claude's softly (oh-so-softly) couched criticisms of my viewpoint, while conceding everywhere Claude expressed subtle (oh-so-subtle) approval of my boss. The call ended shortly afterwards, somewhat awkwardly for both of us. I had just experienced the most baffling mixture of radical transparency and impossible opacity.
Children's Games

I try all things; I achieve what I can.
A year ago, as I was going through a mound of keepsakes my Mom transferred to my custody (I have reached that age, yes), I came across a little book I made in kindergarten describing my first bicycle crash, which I attributed to rolling over a pine-cone. I have very little recollection of the crash itself - I only recall sitting, high up on the passenger seat of the minivan, with a towel pressed to my forehead and anxiously asking, "B-but can you see any BRAINS?"
Redis and the Cost of Ambition

And they said, Go to, let us build us a city and a tower, whose top may reach unto heaven; and let us make us a name, lest we be scattered abroad upon the face of the whole earth.
What happened to dear old Redis, I wondered. And the more I thought about it, a satisfying explanation started to coalesce which explains all the above phenomena. To me, the picture that emerges is that of a solution that lost its identity through ambition.
Tokens and Dreams

The one great principle of the English law is, to make business for itself.
The recurring theme running through my mind the last few months has been complexity within a software application. Forget coding. Sales is using AI to write all new code, so for us engineers there's not a hell of a lot to do besides think (and be there to hold the bag).
cysqlite - a new sqlite driver
![]()
Back in the spring of 2019, I began working on cysqlite,
a from-scratch DB-API compatible SQLite driver. I intended one day to use it as
a replacement for pysqlite3. Seven years later, the project is ready. It provides an API and performance similar to the standard library sqlite3 module, with many additional features.
Ghost in the Shell: my AI Experiment
A man's at odds to know his mind cause his mind is aught he has to know it with. He can know his heart, but he dont want to. Rightly so. Best not to look in there. It aint the heart of a creature that is bound in the way that God has set for it. You can find meanness in the least of creatures, but when God made man the devil was at his elbow. A creature that can do anything. Make a machine. And a machine to make the machine. An evil that can run itself a thousand years, no need to tend it.
This isn't a post about the machines, though. It is always the human builder that comes first and last.
Asyncio Finally Got Peewee

I feel that it is high time that Peewee had an assyncio story. I've avoided this for years, but asyncio is not going anywhere. Peewee remains a synchronous ORM, but in order to work with the ever-widening sphere of async-first web frameworks and database drivers, it was time to come up with a plan.
AsyncIO

I'd like to put forth my current thinking about asyncio. I hope this will answer some of the questions I've received as to whether Peewee will one day support asyncio, but moreso I hope it will encourage some readers (especially in the web development crowd) to question whether asyncio is appropriate for their project, and if so, look into alternatives like gevent.

Caching trick for Python web applications
I'd like to share a simple trick I use to reduce roundtrips pulling data from a cache server (like Redis or Kyoto Tycoon. Both Redis and Kyoto Tycoon support efficient bulk-get operations, so it makes sense to read as many keys from the cache as we can when performing an operation that may need to access multiple cached values. This is especially true in web applications, as a typical web-page may multiple chunks of data and rendered HTML from a cache (fragment-caching) to build the final page that is sent as a response.
If we know ahead-of-time which cache-keys we need to fetch, we could just grab the cached data in one Redis/KT request and hold onto it in memory for the duration of the request.
Peewee now supports CockroachDB

I'm pleased to announce that Peewee now supports CockroachDB (CRDB), the distributed, horizontally-scalable SQL database. I'm excited about this release, because it's now quite easy to get up-and-running with a robust SQL database that can scale out with minimal effort (documentation).
Here is how you configure a CockroachDatabase instance:
from playhouse.cockroachdb import CockroachDatabase
db = CockroachDatabase('my_app', user='root', host='10.1.0.8', port=26257)
CRDB conveniently provides a very similar SQL dialect to Postgres, which has been
well-supported in Peewee for many years, allowing you to use features like jsonb
and arrays,
in addition to the regular complement of field-types. Additionally, CRDB speaks
the same wire-protocol as Postgres, so it works out-of-the-box using the
popular psycopg2 driver.
New features planned for Python 4.0
With the release of Python 3.8 coming soon, the core development team has asked me to summarize our latest discussions on the new features planned for Python 4.0, codename "ouroboros: the snake will eat itself". This will be an exciting release and a significant milestone, many thanks to the hard work of over 100 contributors.
ucache, a lightweight caching library for python
![]()
I recently wrote about Kyoto Tycoon (KT), a fast key/value database server. KT databases may be ordered (B-Tree / red-black tree) or unordered (hash table), and persistent or stored completely in-memory. Among other things, I'm using KT's hash database as a cache for things like HTML fragments, RSS feed data, etc. KT supports automatic, time-based expiration, so using it as a cache is a natural fit.
Besides using KT as a cache, in the past I have also used Redis and Sqlite. So I've released a small library I'm calling ucache which can be used with these storage backends and has a couple nice features. I will likely flesh it out and add support for additional storages as I find time to work on it.
My new and improved server-error page
I saw an excellent article recently describing how to implement the fire effect seen in the trailer for the N64/PlayStation ports of the DooM game. I figured this would be neat to put on the page displayed whenever there's a server error. I already have an awesome 404 page, and now I'm equally happy with the 500 page.
Kyoto Tycoon in 2019
![]()
I've been interested in using Kyoto Tycoon for some time. Kyoto Tycoon, successor to Tokyo Tyrant, is a key/value database with a number of desirable features:
- On-disk hash table for fast random access
- On-disk b-tree for ordered collections
- Server supports thousands of concurrent connections
- Embedded lua scripting
- Asynchronous replication, hot backups, update logging
- Exceptional performance
Multi-process task queue using Redis Streams
In this post I'll present a short code snippet demonstrating how to use Redis streams to implement a multi-process task queue with Python. Task queues are commonly-used in web-based applications, as they allow decoupling time-consuming computation from the request/response cycle. For example when someone submits the "contact me" form, the webapp puts a message onto a task queue, so that the relatively time-consuming process of checking for spam and sending an email occurs outside the web request in a separate worker process.
queue = TaskQueue('my-queue')
@queue.task
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return b
# Calculate 100,000th fibonacci number in worker process.
fib100k = fib(100000)
# Block until the result becomes ready, then display last 6 digits.
print('100,000th fibonacci ends with: %s' % str(fib100k())[-6:])
When using Redis as a message broker, I've always favored using LPUSH/BRPOP (left-push, blocking right-pop) to enqueue and dequeue a message. Pushing items onto a list ensures that messages will not be lost if the queue is growing faster than it can be processed – messages just get added until the consumer(s) catch up. Blocking right-pop is an atomic operation, so Redis also guarantees that no matter how many consumers you've got listening for messages, each message is delivered to only one consumer.
There are some downsides to using lists, primarily the fact that blocking right-pop is a destructive read. Once a message is read, the application can no longer tell whether the message was processed successfully or has failed and needs to be retried. Similarly, there is no visibility into which consumer processed a given message.
Redis 5.0 includes a new streams data-type for modelling append-only, persistent message logging. Streams are identified by a key, like other data-types, and support append, read and delete operations. Streams provide a number of benefits over other data-types typically used for building distributed task queues using Redis, particularly when used with consumer groups.
- Streams support fan-out message delivery to all interested readers (kinda like pub/sub), or you can use consumer groups to ensure that messages are distributed evenly among a pool of consumers (like lpush/brpop).
- Messages are persistent and history is kept around, even after a message has been read by a consumer.
- Message delivery information is tracked by Redis, making it easy to identify which tasks were completed successfully, and which failed and need to be retried (at the cost of an explicit ACK).
- Messages are structured as any number of arbitrary key/value pairs, providing a bit more internal structure than an opaque blob stored in a list.
Consumer groups provide us with a unified interface for managing message delivery and querying the status of the task queue. These features make Redis a nice option if you need a message broker.
Introduction to Redis streams with Python
![]()
Redis 5.0 contains, among lots of fixes and improvements, a new data-type and set of commands for working with persistent, append-only streams.
Redis streams are a complex topic, so I won't be covering all aspects of the APIs, but hopefully after reading this post you'll have a feel for how they work and whether they might be useful in your own projects.
Streams share some superficial similarities with list operations and pub/sub, with some important differences. For instance, task queues are commonly implemented by having multiple workers issue blocking-pop operations on a list. The benefit of this approach is that messages are distributed evenly among the available workers. Downsides, however, are:
- Once a message is read it's effectively "gone forever". If the worker crashes there's no way to tell if the message was processed or needs to be rescheduled. This pushes the responsibility of retrying failed operations onto the consumer.
- Only one client can read a given message. There's no "fan-out".
- No visibility into message state after the message is read.
Similarly, Redis pub/sub can be used to publish a stream of messages to any number of interested consumers. Pub/sub is limited by the fact that it is "fire and forget". There is no history, nor is there any indication that a message has been read.
Streams allow the implementation of more robust message processing workflows, thanks to the following features:
- streams allow messages to be fanned-out to multiple consumers or you can use stateful consumers ("consumer groups") to coordinate message processing among multiple workers.
- message history is preserved and visible to other clients.
- consumer groups support message acknowledgements, claiming stale unacknowledged messages, and introspecting pending messages, ensuring that messages are not lost in the event of an application crash.
- streams support blocking read operations.
The rest of the post will show some examples of working with streams using the walrus Redis library. If you prefer to just read the code, this post is also available as an ipython notebook.
Creating a standalone Python driver for BerkeleyDB's SQLite front-end

In this post I'll provide instructions for building a standalone Python sqlite3-compatible module which is powered by BerkeleyDB. This is possible because BerkeleyDB provides a SQL frontend, which essentially is the SQLite we all know and love with the b-tree code ripped out and replaced with BerkeleyDB.
Misadventures in Python Packaging: Optional C Extensions
I began an unlikely adventure into Python packaging this week when I made what
I thought were some innocuous modifications to the source distribution and
setup.py script for the peewee
database library. Over the course of a day, the setup.py more than doubled in
size and underwent five major revisions as I worked to fix problems arising out
of various differences in users environments. This was tracked in issue #1676,
may it always bear witness to the complexities of Python packaging!
In this post I'll explain what happened, the various things I tried, and how I ended up resolving the issue.
Compiling SQLite for use with Python Applications
The upcoming SQLite 3.25.0 release adds support for one of my favorite SQL language features: window functions. Over the past few years SQLite has released many changes to improve the efficiency of the query planner and virtual machine, plus many extension modules which can provide additional functionality. For example:
- Window function support,
which are available in
trunkand will be included in the next release (3.25.0). - Postgresql-style UPSERT support, which was released on 2018-06-04 (3.24.0).
- FTS5 full-text search extension, which improves on the previous full-text search modules (3.9.0).
- json1 extension, which brings support for JSON to SQLite (3.9.0).
- lsm1 extension and virtual table, while not officially released, is included in the source.
- Eponymous-only virtual tables, or table-valued functions (3.9.0).
- csv virtual table for browsing CSVs directly with SQLite (3.14.0).
Unfortunately, many distributions and operating systems include very old versions of SQLite. When they do include a newer release, typically many of these additional modules are not compiled and are therefore unavailable for use in your Python applications.
In this post I'll walk through obtaining the latest version of SQLite's source code and how to compile it so it includes these exciting features. We'll be doing all of this with the goal of being able to use these features in our Python applications, so we'll also be discussing how to integrate Python with our custom SQLite library.
Kyoto Tycoon and Tokyo Tyrant with Python
![]()
I recently open-sourced a Python library for working with the networked key/value databases Kyoto Tycoon and Tokyo Tyrant. These databases sit atop Kyoto Cabinet and Tokyo Cabinet, respectively, and provide fast DBM implementations.
The Cabinet libraries expose a familiar key/value API backed by a number of different storage options, including persistent hash-tables and b-trees, as well as in-memory variants. A cabinet database can only be accessed by a single process at any given time, though they can be used safely in multi-threaded environments. For this reason, the author created an evented network layer that can expose these storage interfaces to multiple processes. These database servers are Kyoto Tycoon and Tokyo Tyrant, and in addition to providing a fast front-end to the underlying storage engines, they can add features like lua scripting, multi-master replication and LRU cache eviction.
Some scenarios in which you might find these databases useful:
- Memcached or Redis replacement. The LRU eviction provided by Kyoto Tycoon, combined with being scriptable with Lua, and backed with persistent storage, allows these databases to go beyond traditional key/value database roles.
- Time-series and event-logging. The B-Tree storage engine supports fast range scans and ordered key traversal, for rolling-up events, map/reduce workflows, and reporting.
- Full-text search, using the hash storage engine.
- Secondary indexes for external data-stores.
- Document database using lua tables in place of JSON objects.
Features of the kt library:
- Binary protocol support implemented as a C extension.
- Thread-safe and greenlet-safe.
- Simple and memorable APIs.
- Full-featured implementation of the protocols.
- Multiple serialization schemes, including JSON, msgpack and pickle.
If you're interested in trying out these fantastic databases with Python, the documentation for kt can be found here: http://kt-lib.readthedocs.io/en/latest/
Peewee 3.0 released
![]()
On Monday of this week I merged in the 3.0a branch of peewee, a lightweight Python ORM, marking the
official 3.0.0 release
of the project. Today as I'm writing this, the project is at 3.0.9, thanks to
so many helpful people submitting issues and bug reports. Although this was
pretty much a complete rewrite of the 2.x codebase, I have tried to maintain
backwards-compatibility for the public APIs.
In this post I'll discuss a bit about the motivation for the rewrite and some changes to the overall design of the library. If you're thinking about upgrading, check out the changes document and, if you are wondering about any specific APIs, take a spin through the rewritten (and much more thorough) API documentation.
SQLite Database Authorization and Access Control with Python
![]()
The Python standard library sqlite3 driver comes with a barely-documented hook for implementing basic authorization for SQLite databases. Using this hook, it is possible to register a callback that signals, via a return value, what data can be accessed by a connection.
SQLite databases are embedded in the same process as your application, so there is no master server process to act as a gatekeeper for the data stored in your database. Additionally, SQLite database files are readable by anyone with access to the database file itself (unless you are using an encryption library like sqlcipher or sqleet). Restricting access to a SQLite database, once a connection has been opened, is only possible through the use of an authorizer callback.
SQLite provides very granular settings for controlling access, along with two failure modes. Taken together, I think you'll be impressed by the degree of control that is possible.
Write your own miniature Redis with Python
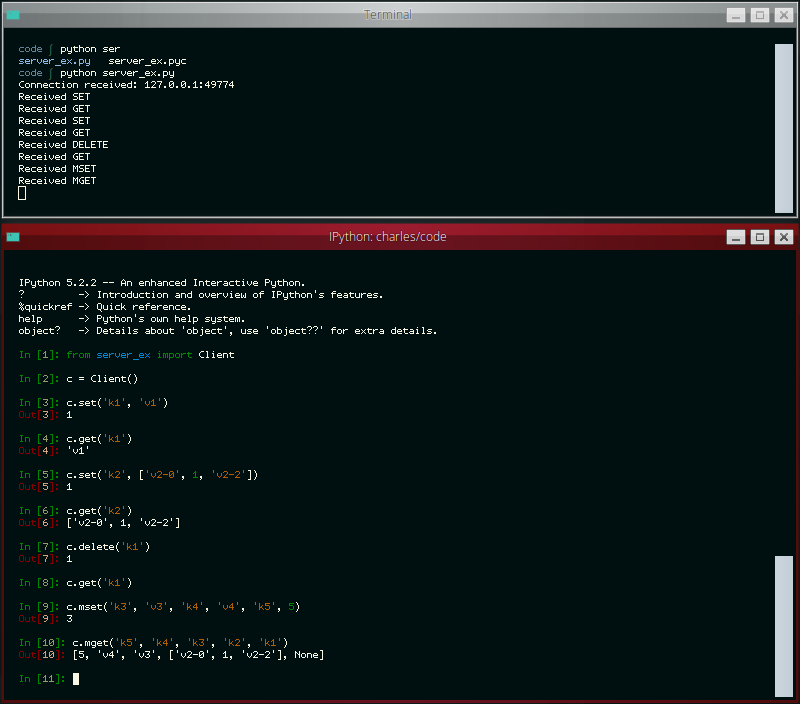
The other day the idea occurred to me that it would be neat to write a simple Redis-like database server. While I've had plenty of experience with WSGI applications, a database server presented a novel challenge and proved to be a nice practical way of learning how to work with sockets in Python. In this post I'll share what I learned along the way.
The goal of my project was to write a simple server that I could use with a task queue project of mine called huey. Huey uses Redis as the default storage engine for tracking enqueued jobs, results of finished jobs, and other things. For the purposes of this post, I've reduced the scope of the original project even further so as not to muddy the waters with code you could very easily write yourself, but if you're curious, you can check out the end result here (documentation).
The server we'll be building will be able to respond to the following commands:
- GET
<key> - SET
<key><value> - DELETE
<key> - FLUSH
- MGET
<key1>...<keyn> - MSET
<key1><value1>...<keyn><valuen>
We'll support the following data-types as well:
- Strings and Binary Data
- Numbers
- NULL
- Arrays (which may be nested)
- Dictionaries (which may be nested)
- Error messages
LSM Key/Value Storage in SQLite3
![]()
Several months ago I was delighted to see a new extension appear in the SQLite source tree. The lsm1 extension is based on the LSM key/value database developed as an experimental storage engine for the now-defunct SQLite4 project. Since development has stopped on SQLite4 for the forseeable future, I was happy to see this technology being folded into SQLite3 and was curious to see what the SQLite developers had in mind for this library.
The SQLite4 LSM captured my interest several years ago as it seemed like a viable alternative to some of the other embedded key/value databases floating around (LevelDB, BerkeleyDB, etc), and I went so far as to write a set of Python bindings for the library. As a storage engine, it seems to offer stable performance, with fast reads of key ranges and fast-ish writes, though random reads may be slower than the usual SQLite3 btree. Like SQLite3, the LSM database supports a single-writer/multiple-reader transactional concurrency model, as well as nested transaction support.
The LSM implementation in SQLite3 is essentially the same as that in SQLite4, plus some additional bugfixes and performance improvements. Crucially, the SQLite3 implementation comes with a standalone extension that exposes the storage engine as a virtual table. The rest of this post will deal with the virtual table, its implementation, and how to use it.
Ditching the Task Queue for Gevent
Task queues are frequently deployed alongside websites to do background processing outside the normal request/response cycle. In the past I've used them for things like sending emails, generating thumbnails, warming caches, or periodically fetching remote resources. By pushing that work out of the request/response cycle, you can increase the throughput (and responsiveness) of your web application.
Depending on your workload, though, it may be possible to move your task processing into the same process as your web server. In this post I'll describe how I did just that using gevent, though the technique would probably work well with a number of different WSGI servers.
Going Fast with SQLite and Python
![]()
In this post I'd like to share with you some techniques for effectively working with SQLite using Python. SQLite is a capable library, providing an in-process relational database for efficient storage of small-to-medium-sized data sets. It supports most of the common features of SQL with few exceptions. Best of all, most Python users do not need to install anything to get started working with SQLite, as the standard library in most distributions ships with the sqlite3 module.


Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.
Optimistic locking in Peewee ORM

In this post I'll share a simple code snippet you can use to perform optimistic locking when updating model instances. I've intentionally avoided providing an implementation for this in peewee, because I don't believe it will be easy to find a one-size-fits-all approach to versioning and conflict resolution. I've updated the documentation to include the sample implementation provided here, however.
Monospace Font Favorites
For the past six months or so, I've been experimenting with a variety of monospace fonts in a quest to find the perfect coding font. While I haven't found a clear winner, I have found a dozen nice-looking fonts and learned a lot about typefaces in general. I've also learned quite a bit about font rendering on Linux, which I hope to summarize in a separate post soon.
In this post I'd like to share some screenshots (or "swatches") of my favorite fonts.
Suffering for fashion: a glimpse into my Linux theming toolchain

My desktop at the time of writing.
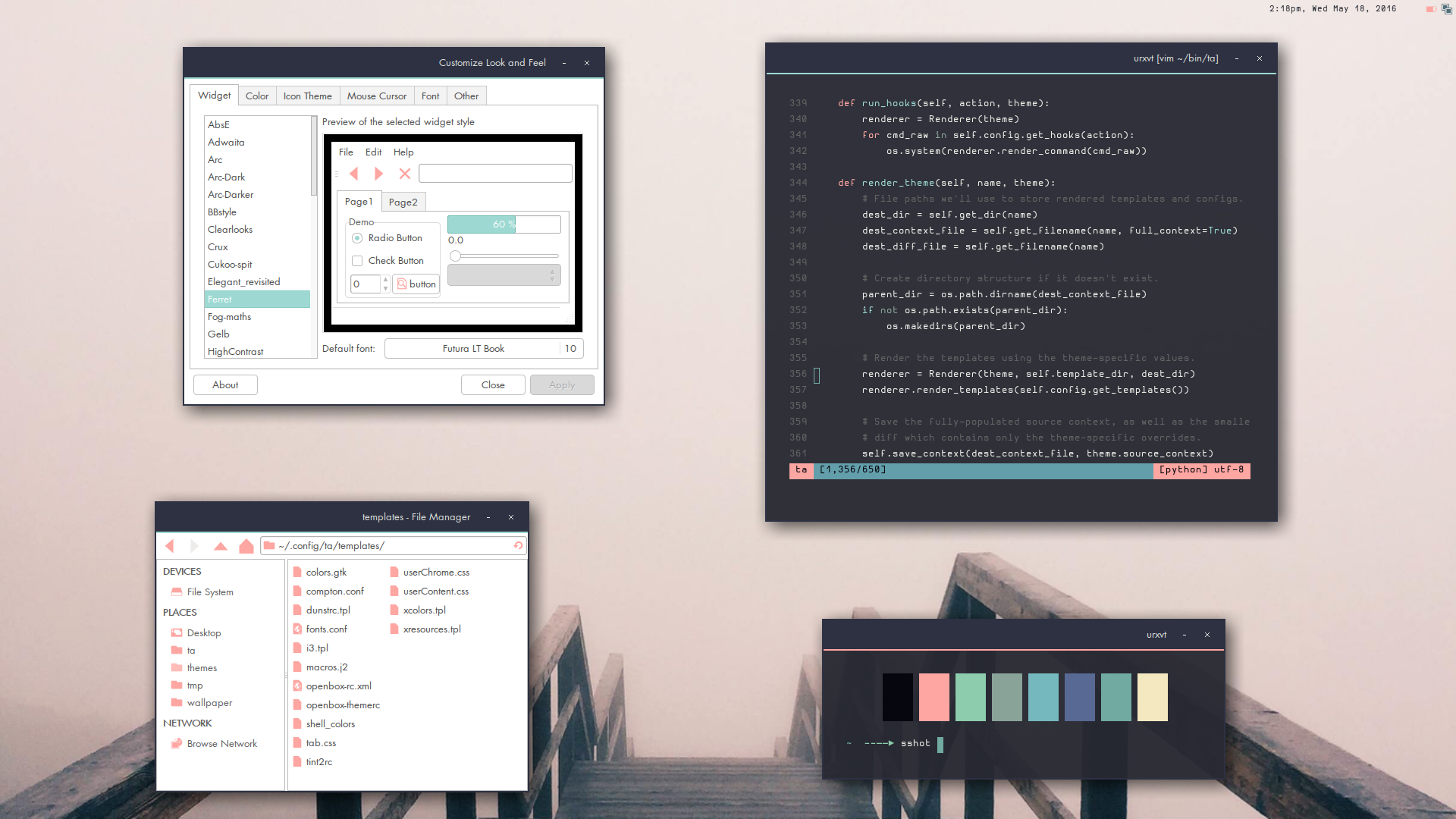
Here it is a couple months later.
It's been over 2 years since I wrote about the tooling I use to theme my desktop, so I thought I'd post about my current scripts...
"For Humans" makes me cringe

When Kenneth Reitz created the requests library, the Python community rushed to embrace the project, as it provided (finally) a clean, sane API for making HTTP requests. He subtitled his project "Python HTTP Requests for Humans", referring, I suppose, to the fact that his API provided developer-friendly APIs. If naming things "for humans" had stopped there, that would have been fine with me, but instead there's been a steady stream of new projects describing themselves as being "For Humans" and I have issues with that.
Measuring Nginx Cache Performance using Lua and Redis

Shortly after launching my Nginx-based cache + thumbnailing web-service, I realized I had no visibility into the performance of the service. I was curious what my hit-ratios were like, how much time was spent during a cache-miss, basic stuff like that. Nginx has monitoring tools, but it looks like they're only available to people who pay for Nginx Plus, so I decided to see if I could roll my own. In this post, I'll describe how I used Lua, cosockets, and Redis to extract real-time metrics from my thumbnail service.
Nginx: a caching, thumbnailing, reverse proxying image server?
![]()
A month or two ago, I decided to remove Varnish from my site and replace it with Nginx's built-in caching system. I was already using Nginx to proxy to my Python sites, so getting rid of Varnish meant one less thing to fiddle with. I spent a few days reading up on how to configure Nginx's cache and overhauling the various config files for my Python sites (so much for saving time). In the course of my reading I bookmarked a number of interesting Nginx modules to return to, among them the Image Filter module.
Five reasons you should use SQLite in 2016
![]()
If you haven't heard, SQLite is an amazing database capable of doing real work in real production environments. In this post, I'll outline 5 reasons why I think you should use SQLite in 2016.
Announcing sophy: fast Python bindings for Sophia Database
![]()
Sophia is a powerful key/value database with loads of features packed into a simple C API. In order to use this database in some upcoming projects I've got planned, I decided to write some Python bindings and the result is sophy. In this post, I'll describe the features of Sophia database, and then show example code using sophy, the Python wrapper.
Here is an overview of the features of the Sophia database:
- Append-only MVCC database
- ACID transactions
- Consistent cursors
- Compression
- Ordered key/value store
- Range searches
- Prefix searches
SQLite Table-Valued Functions with Python
One of the benefits of running an embedded database like SQLite is that you can configure SQLite to call into your application's code. SQLite provides APIs that allow you to create your own scalar functions, aggregate functions, collations, and even your own virtual tables. In this post I'll describe how I used the virtual table APIs to expose a nice API for creating table-valued (or, multi-value) functions in Python. The project is called sqlite-vtfunc and is hosted on GitHub. If you use Peewee, an equivalent implementation is included in the Peewee SQLite extensions.
Using the SQLite JSON1 and FTS5 Extensions with Python
Back in September, word started getting around trendy programming circles about a new file that had appeared in the SQLite fossil repo named json1.c. I originally wrote up a post that contained some gross hacks in order to get pysqlite to compile and work with the new json1 extension. With the release of SQLite 3.9.0, those hacks are no longer necessary.
SQLite 3.9.0 is a fantastic release. In addition to the much anticipated json1 extension, there is a new version of the full-text search extension called fts5. fts5 improves performance of complex search queries and provides an out-of-the-box BM25 ranking implementation. You can also boost the significance of particular fields in the ranking. I suggest you check out the release notes for the full list of enhancements
This post will describe how to compile SQLite with support for json1 and fts5. We'll use the new SQLite library to compile a python driver so we can use the new features from python. Because I really like pysqlite and apsw, I've included instructions for building both of them. Finally, we'll use peewee ORM to run queries using the json1 and fts5 extensions.