Entries tagged with nosql
Kyoto Tycoon in 2019
![]()
I've been interested in using Kyoto Tycoon for some time. Kyoto Tycoon, successor to Tokyo Tyrant, is a key/value database with a number of desirable features:
- On-disk hash table for fast random access
- On-disk b-tree for ordered collections
- Server supports thousands of concurrent connections
- Embedded lua scripting
- Asynchronous replication, hot backups, update logging
- Exceptional performance
Kyoto Tycoon and Tokyo Tyrant with Python
![]()
I recently open-sourced a Python library for working with the networked key/value databases Kyoto Tycoon and Tokyo Tyrant. These databases sit atop Kyoto Cabinet and Tokyo Cabinet, respectively, and provide fast DBM implementations.
The Cabinet libraries expose a familiar key/value API backed by a number of different storage options, including persistent hash-tables and b-trees, as well as in-memory variants. A cabinet database can only be accessed by a single process at any given time, though they can be used safely in multi-threaded environments. For this reason, the author created an evented network layer that can expose these storage interfaces to multiple processes. These database servers are Kyoto Tycoon and Tokyo Tyrant, and in addition to providing a fast front-end to the underlying storage engines, they can add features like lua scripting, multi-master replication and LRU cache eviction.
Some scenarios in which you might find these databases useful:
- Memcached or Redis replacement. The LRU eviction provided by Kyoto Tycoon, combined with being scriptable with Lua, and backed with persistent storage, allows these databases to go beyond traditional key/value database roles.
- Time-series and event-logging. The B-Tree storage engine supports fast range scans and ordered key traversal, for rolling-up events, map/reduce workflows, and reporting.
- Full-text search, using the hash storage engine.
- Secondary indexes for external data-stores.
- Document database using lua tables in place of JSON objects.
Features of the kt library:
- Binary protocol support implemented as a C extension.
- Thread-safe and greenlet-safe.
- Simple and memorable APIs.
- Full-featured implementation of the protocols.
- Multiple serialization schemes, including JSON, msgpack and pickle.
If you're interested in trying out these fantastic databases with Python, the documentation for kt can be found here: http://kt-lib.readthedocs.io/en/latest/
LSM Key/Value Storage in SQLite3
![]()
Several months ago I was delighted to see a new extension appear in the SQLite source tree. The lsm1 extension is based on the LSM key/value database developed as an experimental storage engine for the now-defunct SQLite4 project. Since development has stopped on SQLite4 for the forseeable future, I was happy to see this technology being folded into SQLite3 and was curious to see what the SQLite developers had in mind for this library.
The SQLite4 LSM captured my interest several years ago as it seemed like a viable alternative to some of the other embedded key/value databases floating around (LevelDB, BerkeleyDB, etc), and I went so far as to write a set of Python bindings for the library. As a storage engine, it seems to offer stable performance, with fast reads of key ranges and fast-ish writes, though random reads may be slower than the usual SQLite3 btree. Like SQLite3, the LSM database supports a single-writer/multiple-reader transactional concurrency model, as well as nested transaction support.
The LSM implementation in SQLite3 is essentially the same as that in SQLite4, plus some additional bugfixes and performance improvements. Crucially, the SQLite3 implementation comes with a standalone extension that exposes the storage engine as a virtual table. The rest of this post will deal with the virtual table, its implementation, and how to use it.
Announcing sophy: fast Python bindings for Sophia Database
![]()
Sophia is a powerful key/value database with loads of features packed into a simple C API. In order to use this database in some upcoming projects I've got planned, I decided to write some Python bindings and the result is sophy. In this post, I'll describe the features of Sophia database, and then show example code using sophy, the Python wrapper.
Here is an overview of the features of the Sophia database:
- Append-only MVCC database
- ACID transactions
- Consistent cursors
- Compression
- Ordered key/value store
- Range searches
- Prefix searches
Using SQLite4's LSM Storage Engine as a Stand-alone NoSQL Database with Python

SQLite and Key/Value databases are two of my favorite topics to blog about. Today I get to write about both, because in this post I will be demonstrating a Python wrapper for SQLite4's log-structured merge-tree (LSM) key/value store.
I don't actively follow SQLite's releases, but the recent release of SQLite 3.8.11 drew quite a bit of attention as the release notes described massive performance improvements over 3.8.0. While reading the release notes I happened to see a blurb about a new, experimental full-text search extension, and all this got me to wondering what was going on with SQLite4.
As I was reading about SQLite4, I saw that one of the design goals was to provide an interface for pluggable storage engines. At the time I'm writing this, SQLite4 has two built-in storage backends, one of which is an LSM key/value store. Over the past month or two I've been having fun with Cython, writing Python wrappers for the embedded key/value stores UnQLite and Vedis. I figured it would be cool to use Cython to write a Python interface for SQLite4's LSM storage engine.
After pulling down the SQLite4 source code and reading through the LSM header file (it's very small!), I started coding and the result is python-lsm-db (docs).
Read the rest of the post for examples of how to use the library.
Introduction to the fast new UnQLite Python Bindings
![]()
About a year ago, I blogged about some Python bindings I wrote for the embedded NoSQL document store UnQLite. One year later I'm happy to announce that I've rewritten the library using Cython and operations are, in most cases, an order of magnitude faster.
This was my first real attempt at using Cython and the experience was just the right mix of challenging and rewarding. I bought the O'Reilly Cython Book which came in super handy, so if you're interested in getting started with Cython I recommend picking up a copy.
In this post I'll quickly touch on the features of UnQLite, then show you how to use the Python bindings. When you're done reading you should hopefully be ready to use UnQLite in your next Python project.
Naive Bayes Classifier using Python and Kyoto Cabinet
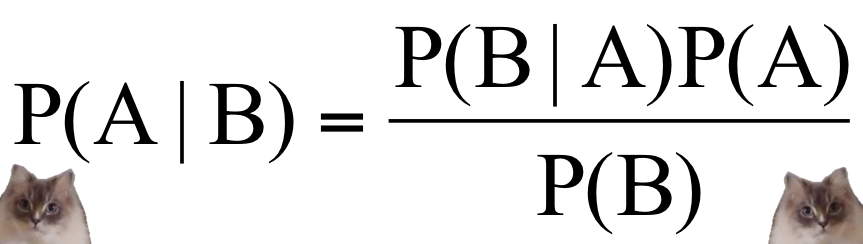
In this post I will describe how to build a simple naive bayes classifier with Python and the Kyoto Cabinet key/value database. I'll begin with a short description of how a probabilistic classifier works, then we will implement a simple classifier and put it to use by writing a spam detector. The training and test data will come from the Enron spam/ham corpora, which contains several thousand emails that have been pre-categorized as spam or ham.
Walrus: Lightweight Python utilities for working with Redis
![]()
A couple weekends ago I got it into my head that I would build a thin Python wrapper for working with Redis. Andy McCurdy's redis-py is a fantastic low-level client library with built-in support for connection-pooling and pipelining, but it does little more than provide an interface to Redis' built-in commands (and rightly so). I decided to build a project on top of redis-py that exposed pythonic containers for the Redis data-types. I went on to add a few extras, including a cache and a declarative model layer. The result is walrus.
Completely un-scientific benchmarks of some embedded databases with Python
I've spent some time over the past couple weeks playing with the embedded NoSQL databases Vedis and UnQLite. Vedis, as its name might indicate, is an embedded data-structure database modeled after Redis. UnQLite is a JSON document store (like MongoDB, I guess??). Beneath the higher-level APIs, both Vedis and UnQLite are key/value stores, which puts them in the same category as BerkeleyDB, KyotoCabinet and LevelDB. The Python standard library also includes some dbm-style databases, including gdbm.
For fun, I thought I would put together a completely un-scientific benchmark showing the relative speeds of these various databases for storing and retrieving simple keys and values.
Here are the databases and drivers that I used for the test:
- UnQLite: unqlite-python (ctypes)
- Vedis: vedis-python (ctypes)
- GDBM: standard library (C)
- BerkeleyDB (b-tree and hash-table): bsddb3 (C)
- KyotoCabinet (b-tree and hash-table): kyotocabinet (C++)
- LevelDB: plyvel (Cython)
- RocksDB: pyrocksdb (Cython)
- SQLite: standard library (C and Python)
- Redis: redis-py (Python) -- this one is just for fun!
I'm running these tests with:
- Linux 3.14.4
- Python 2.7.7 (Py2K 4 lyfe!)
- SSD
For the test, I simply recorded the time it took to store 100K simple key/value pairs (no collisions). Then I recorded the time it took to read back all these values. The results are in seconds elapsed:
