Entries tagged with python
Introduction to the fast new UnQLite Python Bindings
![]()
About a year ago, I blogged about some Python bindings I wrote for the embedded NoSQL document store UnQLite. One year later I'm happy to announce that I've rewritten the library using Cython and operations are, in most cases, an order of magnitude faster.
This was my first real attempt at using Cython and the experience was just the right mix of challenging and rewarding. I bought the O'Reilly Cython Book which came in super handy, so if you're interested in getting started with Cython I recommend picking up a copy.
In this post I'll quickly touch on the features of UnQLite, then show you how to use the Python bindings. When you're done reading you should hopefully be ready to use UnQLite in your next Python project.
A Tour of Tagging Schemas: Many-to-many, Bitmaps and More

In this post I'll describe how to implement tagging with a relational database. What I mean by tagging are those little labels you see at the top of this blog post, which indicate how I've chosen to categorize the content. There are many ways to solve this problem, and I'll try to describe some of the more popular methods, as well as one unconventional approach using bitmaps. In each section I'll describe the database schema, try to list the benefits and drawbacks, and present example queries. I will use Peewee ORM for the example code, but hopefully these examples will easily translate to your tool-of-choice.
Meet Scout, a Search Server Powered by SQLite

In my continuing adventures with SQLite, I had the idea of writing a RESTful search server utilizing SQLite's full-text search extension. You might think of it as a poor man's ElasticSearch.
So what is this project? Well, the idea I had was that instead of building out separate search implementations for my various projects, I would build a single lightweight search service I could use everywhere. I really like SQLite (and have previously blogged about using SQLite's full-text search with Python), and the full-text search extension is quite good, so it didn't require much imagination to take the next leap and expose it as a web-service.
Read on for more details.
How to make a Flask blog in one hour or less
For fun, I thought I'd write a post describing how to build a blog using Flask, a Python web-framework. Building a blog seems like, along with writing a Twitter-clone, a quintessential experience when learning a new web framework. I remember when I was attending a five-day Django tutorial presented by Jacob Kaplan-Moss, one of my favorite projects we did was creating a blog. After setting up the core of the site, I spent a ton of time adding features and little tweaks here-and-there. My hope is that this post will give you the tools to build a blog, and that you have fun customizing the site and adding cool new features.
In this post we'll cover the basics to get a functional site, but leave lots of room for personalization and improvements so you can make it your own. The actual Python source code for the blog will be a very manageable 200 lines.
Who is this post for?
This post is intended for beginner to intermediate-level Python developers, or experienced developers looking to learn a bit more about Python and Flask. For the mother of all Flask tutorials, check out Miguel Grinberg's 18 part Flask mega-tutorial.
The spec
Here are the features:
- Entries are formatted using markdown.
- Entries support syntax highlighting, optionally using Github-style triple-backticks.
- Automatic video / rich media embedding using OEmbed.
- Very nice full-text search thanks to SQLite's FTS extension.
- Pagination.
- Draft posts.
Querying the top N objects per group with Peewee ORM

This post is a follow-up to my post about querying the top related item by group. In this post we'll go over ways to retrieve the top N related objects by group using the Peewee ORM. I've also presented the SQL and the underlying ideas behind the queries, so you can translate them to whatever ORM / query layer you are using.
Retrieving the top N per group is a pretty common task, for example:
- Display my followers and their 10 most recent tweets.
- In each of my inboxes, list the 5 most recent unread messages.
- List the sections of the news site and the three latest stories in each.
- List the five best sales in each department.
In this post we'll discuss the following types of solutions:
- Solutions involving
COUNT() - Solutions involving
LIMIT - Window functions
- Postgresql lateral joins
Querying the top item by group with peewee ORM
In this post I'd like to share some techniques for querying the top item by group using the Peewee ORM. For example,
- List the most recent tweet by each of my followers.
- List the highest severity open bug for each of my open source projects.
- List the latest story in each section of a news site.
This is a common task, but one that can be a little tricky to implement in a single SQL query. To add a twist, we won't use window functions or other special SQL constructs, since they aren't supported by SQLite. If you're interested in finding the top N items per group, check out this follow-up post.
Naive Bayes Classifier using Python and Kyoto Cabinet
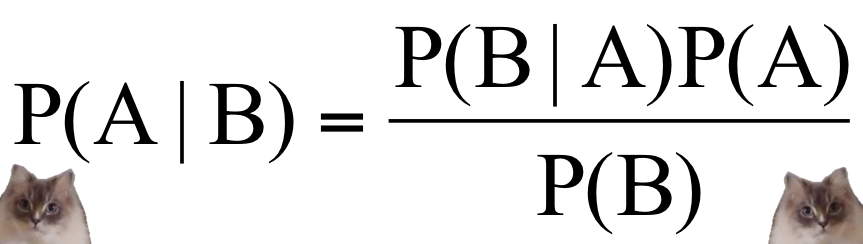
In this post I will describe how to build a simple naive bayes classifier with Python and the Kyoto Cabinet key/value database. I'll begin with a short description of how a probabilistic classifier works, then we will implement a simple classifier and put it to use by writing a spam detector. The training and test data will come from the Enron spam/ham corpora, which contains several thousand emails that have been pre-categorized as spam or ham.
Walrus: Lightweight Python utilities for working with Redis
![]()
A couple weekends ago I got it into my head that I would build a thin Python wrapper for working with Redis. Andy McCurdy's redis-py is a fantastic low-level client library with built-in support for connection-pooling and pipelining, but it does little more than provide an interface to Redis' built-in commands (and rightly so). I decided to build a project on top of redis-py that exposed pythonic containers for the Redis data-types. I went on to add a few extras, including a cache and a declarative model layer. The result is walrus.
Extending SQLite with Python

SQLite is an embedded database, which means that instead of running as a separate server process, the actual database engine resides within the application. This makes it possible for the database to call directly into the application when it would be beneficial to add some low-level, application-specific functionality. SQLite provides numerous hooks for inserting user code and callbacks, and, through virtual tables, it is even possible to construct a completely user-defined table. By extending the SQL language with Python, it is often possible to express things more elegantly than if we were to perform calculations after the fact.
In this post I'll describe how to extend SQLite with Python, adding functions and aggregates that will be callable directly from any SQL queries you execute. We'll wrap up by looking at SQLite's virtual table mechanism and seeing how to expose a SQL interface over external data sources.
Querying Tree Structures in SQLite using Python and the Transitive Closure Extension

I recently read a good write-up on tree structures in PostgreSQL. Hierarchical data is notoriously tricky to model in a relational database, and a variety of techniques have grown out of developers' attempts to optimize for certain types of queries.
In his post, Graeme describes several approaches to modeling trees, including:
- Adjancency models, in which each node in the tree contains a foreign key to its parent row.
- Materialized path model, in which each node stores its ancestral path in a denormalized column. Typically the path is stored as a string separated by a delimiter, e.g. "{root id}.{child id}.{grandchild id}".
- Nested sets, in which each node defines an interval that encompasses a range of child nodes.
- PostgreSQL arrays, in which the materialized path is stored in an array, and general inverted indexes are used to efficiently query the path.
In the comments, some users pointed out that the ltree extension could also be used to efficiently store and query materialized paths. LTrees support two powerful query languages (lquery and ltxtquery) for pattern-matching LTree labels and performing full-text searches on labels.
One technique that was not discussed in Graeme's post was the use of closure tables. A closure table is a many-to-many junction table storing all relationships between nodes in a tree. It is related to the adjacency model, in that each database row still stores a reference to its parent row. The closure table gets its name from the additional table, which stores each combination of ancestor/child nodes.