Welcome! I'm a software engineer and I like blogging about Python, databases, and programming in general. I'm the author of several open-source Python libraries including Peewee ORM, Huey task queue and lots more. Below you can find a list of my most recent blog posts.
If you don't know what your'e doing here, check out some of my popular posts.
Zero AI-generated content.
-
Peewee 4: Async, JSON, Eager-Loading and Types

If you listen real close you can hear the type whispers in there.
Peewee 4.x is a picture, in code, of me eating my hat. We got async and are shipping a significantly better type whispering stub based on typeshed's original. Beyond those, I've added a core
JSONFieldwhich exposes a nice cross-backend API for working with JSON data, and a new declarative API for eager-loading relations.Read on for the details.
-
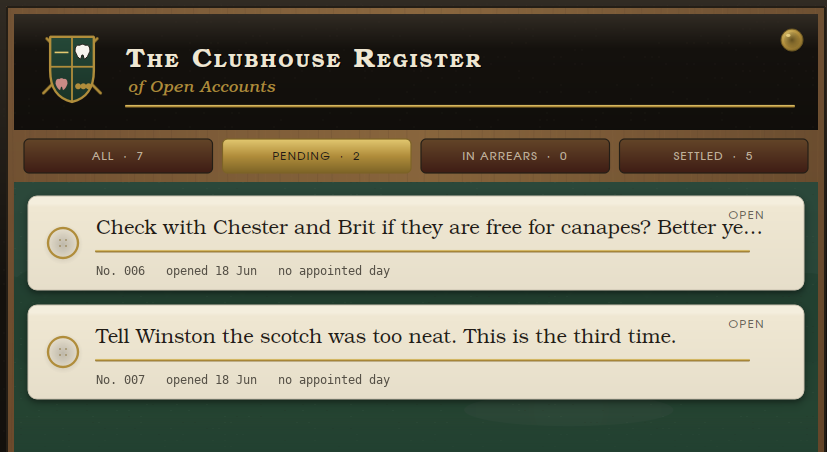
Aspirational Clownmaxxing and Joey's cadillac todo list

Let's build a mid-century country-club-core todo-list app with Python, I thought. But, wait, another voice seemed to say, let's have Claude build us the mid-century country-club-core todo-list app with Python. I put down my dino grabber (🦖), rolled up my sleeves and began writing some prompts.
Here's a taste:
The overall UI paradigm is mid-century country-club-core. You must synthesize a 1000 word essay on this aesthetic, briefly discussing historicity and then delving into meaning in the high form of expression it found in its later periods.
-
Tokens and Dreams

The one great principle of the English law is, to make business for itself.
At work we were talking about metrics. Well, they were talking about metrics, and then when they realized they had none, they asked me to generate some. I spent an hour or so putting together a script that pulled all the relevant historical data from our database, cleaned and normalized into a CSV. Then I fed the CSV into AI. With only a sentence or two of prompt, AI extrapolated meaningful signals, produced no less than 5 graphs, and correlated the data with external market signals which were not explicit in the data-set. It also built a polished interactive dashboard. A dashboard! A dashboard! I've said it in my head so many times I don't even know what it fucking means. Dash board. But I know this: Everyone wants dashboards. AI knows it, too.
-
Hall of Mirrors

Who is he that hideth counsel without knowledge? therefore have I uttered that I understood not; things too wonderful for me, which I knew not.
"Hold on a sec-". My new boss' now-familiar MacOS desktop appeared in the video call, browser with Claude open, dominating the screen. I watched as he copied the transcript of our call up to that point (he records transcripts of every call in order to feed the text into AI), and began a new chat with the prompt: "Say where Charlie's right, and where he's wrong. Say where I'm right and where I'm wrong." He pasted the transcript and hit enter. I consulted my avatar in the lower-right. We both waited in silence while Claude thought. We were 45 minutes into a call about product roadmap and a possible customer announcement before this interruption. Soon the cursor started skipping along as words began filling the screen. Then, we read aloud through the findings one-by-one. Claude had helpfully given us a bulleted list to work through, an even number of findings for each of us. I felt called-upon to gallantly agree with Claude's softly (oh-so-softly) couched criticisms of my viewpoint, while conceding everywhere Claude expressed subtle (oh-so-subtle) approval of my boss. The call ended shortly afterwards, somewhat awkwardly for both of us. I had just experienced the most baffling mixture of radical transparency and impossible opacity.
-
Children's Games

I try all things; I achieve what I can.
A year ago, as I was going through a mound of keepsakes my Mom transferred to my custody (I have reached that age, yes), I came across a little book I made in kindergarten describing my first bicycle crash, which I attributed to rolling over a pine-cone. I have very little recollection of the crash itself - I only recall sitting, high up on the passenger seat of the minivan, with a towel pressed to my forehead and anxiously asking, "B-but can you see any BRAINS?"
View more posts