Entries tagged with redis
Redis and the Cost of Ambition

And they said, Go to, let us build us a city and a tower, whose top may reach unto heaven; and let us make us a name, lest we be scattered abroad upon the face of the whole earth.
What happened to dear old Redis, I wondered. And the more I thought about it, a satisfying explanation started to coalesce which explains all the above phenomena. To me, the picture that emerges is that of a solution that lost its identity through ambition.
Caching trick for Python web applications
I'd like to share a simple trick I use to reduce roundtrips pulling data from a cache server (like Redis or Kyoto Tycoon. Both Redis and Kyoto Tycoon support efficient bulk-get operations, so it makes sense to read as many keys from the cache as we can when performing an operation that may need to access multiple cached values. This is especially true in web applications, as a typical web-page may multiple chunks of data and rendered HTML from a cache (fragment-caching) to build the final page that is sent as a response.
If we know ahead-of-time which cache-keys we need to fetch, we could just grab the cached data in one Redis/KT request and hold onto it in memory for the duration of the request.
ucache, a lightweight caching library for python
![]()
I recently wrote about Kyoto Tycoon (KT), a fast key/value database server. KT databases may be ordered (B-Tree / red-black tree) or unordered (hash table), and persistent or stored completely in-memory. Among other things, I'm using KT's hash database as a cache for things like HTML fragments, RSS feed data, etc. KT supports automatic, time-based expiration, so using it as a cache is a natural fit.
Besides using KT as a cache, in the past I have also used Redis and Sqlite. So I've released a small library I'm calling ucache which can be used with these storage backends and has a couple nice features. I will likely flesh it out and add support for additional storages as I find time to work on it.
Multi-process task queue using Redis Streams
In this post I'll present a short code snippet demonstrating how to use Redis streams to implement a multi-process task queue with Python. Task queues are commonly-used in web-based applications, as they allow decoupling time-consuming computation from the request/response cycle. For example when someone submits the "contact me" form, the webapp puts a message onto a task queue, so that the relatively time-consuming process of checking for spam and sending an email occurs outside the web request in a separate worker process.
queue = TaskQueue('my-queue')
@queue.task
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return b
# Calculate 100,000th fibonacci number in worker process.
fib100k = fib(100000)
# Block until the result becomes ready, then display last 6 digits.
print('100,000th fibonacci ends with: %s' % str(fib100k())[-6:])
When using Redis as a message broker, I've always favored using LPUSH/BRPOP (left-push, blocking right-pop) to enqueue and dequeue a message. Pushing items onto a list ensures that messages will not be lost if the queue is growing faster than it can be processed – messages just get added until the consumer(s) catch up. Blocking right-pop is an atomic operation, so Redis also guarantees that no matter how many consumers you've got listening for messages, each message is delivered to only one consumer.
There are some downsides to using lists, primarily the fact that blocking right-pop is a destructive read. Once a message is read, the application can no longer tell whether the message was processed successfully or has failed and needs to be retried. Similarly, there is no visibility into which consumer processed a given message.
Redis 5.0 includes a new streams data-type for modelling append-only, persistent message logging. Streams are identified by a key, like other data-types, and support append, read and delete operations. Streams provide a number of benefits over other data-types typically used for building distributed task queues using Redis, particularly when used with consumer groups.
- Streams support fan-out message delivery to all interested readers (kinda like pub/sub), or you can use consumer groups to ensure that messages are distributed evenly among a pool of consumers (like lpush/brpop).
- Messages are persistent and history is kept around, even after a message has been read by a consumer.
- Message delivery information is tracked by Redis, making it easy to identify which tasks were completed successfully, and which failed and need to be retried (at the cost of an explicit ACK).
- Messages are structured as any number of arbitrary key/value pairs, providing a bit more internal structure than an opaque blob stored in a list.
Consumer groups provide us with a unified interface for managing message delivery and querying the status of the task queue. These features make Redis a nice option if you need a message broker.
Introduction to Redis streams with Python
![]()
Redis 5.0 contains, among lots of fixes and improvements, a new data-type and set of commands for working with persistent, append-only streams.
Redis streams are a complex topic, so I won't be covering all aspects of the APIs, but hopefully after reading this post you'll have a feel for how they work and whether they might be useful in your own projects.
Streams share some superficial similarities with list operations and pub/sub, with some important differences. For instance, task queues are commonly implemented by having multiple workers issue blocking-pop operations on a list. The benefit of this approach is that messages are distributed evenly among the available workers. Downsides, however, are:
- Once a message is read it's effectively "gone forever". If the worker crashes there's no way to tell if the message was processed or needs to be rescheduled. This pushes the responsibility of retrying failed operations onto the consumer.
- Only one client can read a given message. There's no "fan-out".
- No visibility into message state after the message is read.
Similarly, Redis pub/sub can be used to publish a stream of messages to any number of interested consumers. Pub/sub is limited by the fact that it is "fire and forget". There is no history, nor is there any indication that a message has been read.
Streams allow the implementation of more robust message processing workflows, thanks to the following features:
- streams allow messages to be fanned-out to multiple consumers or you can use stateful consumers ("consumer groups") to coordinate message processing among multiple workers.
- message history is preserved and visible to other clients.
- consumer groups support message acknowledgements, claiming stale unacknowledged messages, and introspecting pending messages, ensuring that messages are not lost in the event of an application crash.
- streams support blocking read operations.
The rest of the post will show some examples of working with streams using the walrus Redis library. If you prefer to just read the code, this post is also available as an ipython notebook.
Write your own miniature Redis with Python
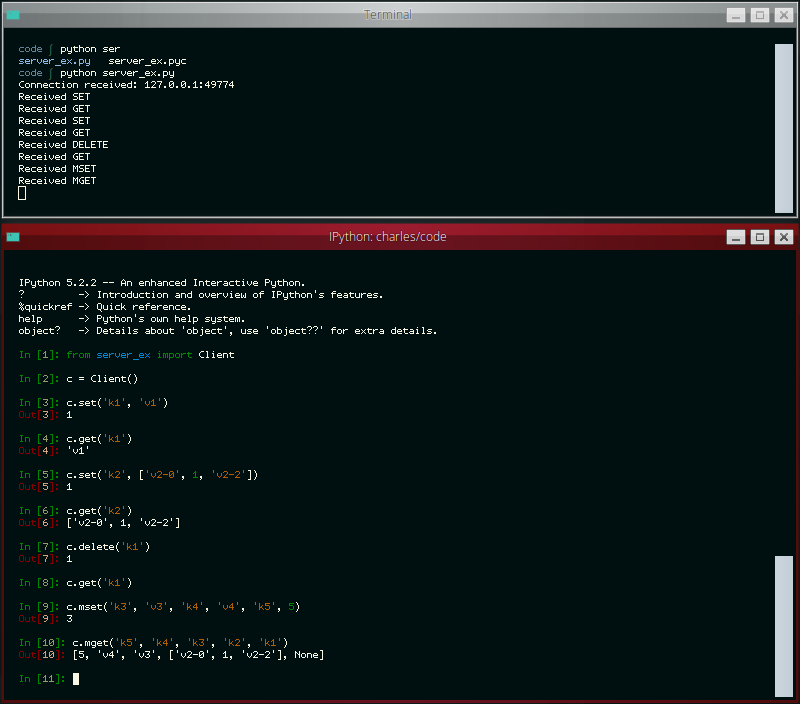
The other day the idea occurred to me that it would be neat to write a simple Redis-like database server. While I've had plenty of experience with WSGI applications, a database server presented a novel challenge and proved to be a nice practical way of learning how to work with sockets in Python. In this post I'll share what I learned along the way.
The goal of my project was to write a simple server that I could use with a task queue project of mine called huey. Huey uses Redis as the default storage engine for tracking enqueued jobs, results of finished jobs, and other things. For the purposes of this post, I've reduced the scope of the original project even further so as not to muddy the waters with code you could very easily write yourself, but if you're curious, you can check out the end result here (documentation).
The server we'll be building will be able to respond to the following commands:
- GET
<key> - SET
<key><value> - DELETE
<key> - FLUSH
- MGET
<key1>...<keyn> - MSET
<key1><value1>...<keyn><valuen>
We'll support the following data-types as well:
- Strings and Binary Data
- Numbers
- NULL
- Arrays (which may be nested)
- Dictionaries (which may be nested)
- Error messages
Measuring Nginx Cache Performance using Lua and Redis

Shortly after launching my Nginx-based cache + thumbnailing web-service, I realized I had no visibility into the performance of the service. I was curious what my hit-ratios were like, how much time was spent during a cache-miss, basic stuff like that. Nginx has monitoring tools, but it looks like they're only available to people who pay for Nginx Plus, so I decided to see if I could roll my own. In this post, I'll describe how I used Lua, cosockets, and Redis to extract real-time metrics from my thumbnail service.
Walrus: Lightweight Python utilities for working with Redis
![]()
A couple weekends ago I got it into my head that I would build a thin Python wrapper for working with Redis. Andy McCurdy's redis-py is a fantastic low-level client library with built-in support for connection-pooling and pipelining, but it does little more than provide an interface to Redis' built-in commands (and rightly so). I decided to build a project on top of redis-py that exposed pythonic containers for the Redis data-types. I went on to add a few extras, including a cache and a declarative model layer. The result is walrus.
Powerful autocomplete with Redis in under 200 lines of Python
In this post I'll present how I built a (reasonably) powerful autocomplete engine with Redis and python. For those who are not familiar with Redis, it is a fast, in-memory, single-threaded database that is capable of storing structured data (lists, hashes, sets, sorted sets). I chose Redis for this particular project because its sorted set data type, which is a good fit for autocomplete. The engine I'll describe relies heavily on Redis' sorted sets and its set operations, but can easily be translated to a pure-python solution (links at bottom of post).
Update
Redis-completion is now deprecated. The autocomplete functionality, along with a number of other features, have been integrated into a new project walrus. Check out the walrus blog announcement for more details.