Blog Entries all / by tag / by year / popular
Peewee 4: Async, JSON, Eager-Loading and Types

If you listen real close you can hear the type whispers in there.
Peewee 4.x is a picture, in code, of me eating my hat. We got async
and are shipping a significantly better type whispering
stub based on typeshed's original. Beyond those, I've added a core JSONField
which exposes a nice cross-backend API for working with JSON data, and a new
declarative API for eager-loading relations.
Read on for the details.
Aspirational Clownmaxxing and Joey's cadillac todo list
Let's build a mid-century country-club-core todo-list app with Python, I thought. But, wait, another voice seemed to say, let's have Claude build us the mid-century country-club-core todo-list app with Python. I put down my dino grabber (🦖), rolled up my sleeves and began writing some prompts.
Here's a taste:
The overall UI paradigm is mid-century country-club-core. You must synthesize a 1000 word essay on this aesthetic, briefly discussing historicity and then delving into meaning in the high form of expression it found in its later periods.
Tokens and Dreams

The one great principle of the English law is, to make business for itself.
At work we were talking about metrics. Well, they were talking about metrics, and then when they realized they had none, they asked me to generate some. I spent an hour or so putting together a script that pulled all the relevant historical data from our database, cleaned and normalized into a CSV. Then I fed the CSV into AI. With only a sentence or two of prompt, AI extrapolated meaningful signals, produced no less than 5 graphs, and correlated the data with external market signals which were not explicit in the data-set. It also built a polished interactive dashboard. A dashboard! A dashboard! I've said it in my head so many times I don't even know what it fucking means. Dash board. But I know this: Everyone wants dashboards. AI knows it, too.
Hall of Mirrors

Who is he that hideth counsel without knowledge? therefore have I uttered that I understood not; things too wonderful for me, which I knew not.
"Hold on a sec-". My new boss' now-familiar MacOS desktop appeared in the video call, browser with Claude open, dominating the screen. I watched as he copied the transcript of our call up to that point (he records transcripts of every call in order to feed the text into AI), and began a new chat with the prompt: "Say where Charlie's right, and where he's wrong. Say where I'm right and where I'm wrong." He pasted the transcript and hit enter. I consulted my avatar in the lower-right. We both waited in silence while Claude thought. We were 45 minutes into a call about product roadmap and a possible customer announcement before this interruption. Soon the cursor started skipping along as words began filling the screen. Then, we read aloud through the findings one-by-one. Claude had helpfully given us a bulleted list to work through, an even number of findings for each of us. I felt called-upon to gallantly agree with Claude's softly (oh-so-softly) couched criticisms of my viewpoint, while conceding everywhere Claude expressed subtle (oh-so-subtle) approval of my boss. The call ended shortly afterwards, somewhat awkwardly for both of us. I had just experienced the most baffling mixture of radical transparency and impossible opacity.
Children's Games

I try all things; I achieve what I can.
A year ago, as I was going through a mound of keepsakes my Mom transferred to my custody (I have reached that age, yes), I came across a little book I made in kindergarten describing my first bicycle crash, which I attributed to rolling over a pine-cone. I have very little recollection of the crash itself - I only recall sitting, high up on the passenger seat of the minivan, with a towel pressed to my forehead and anxiously asking, "B-but can you see any BRAINS?"
Redis and the Cost of Ambition

And they said, Go to, let us build us a city and a tower, whose top may reach unto heaven; and let us make us a name, lest we be scattered abroad upon the face of the whole earth.
What happened to dear old Redis, I wondered. And the more I thought about it, a satisfying explanation started to coalesce which explains all the above phenomena. To me, the picture that emerges is that of a solution that lost its identity through ambition.
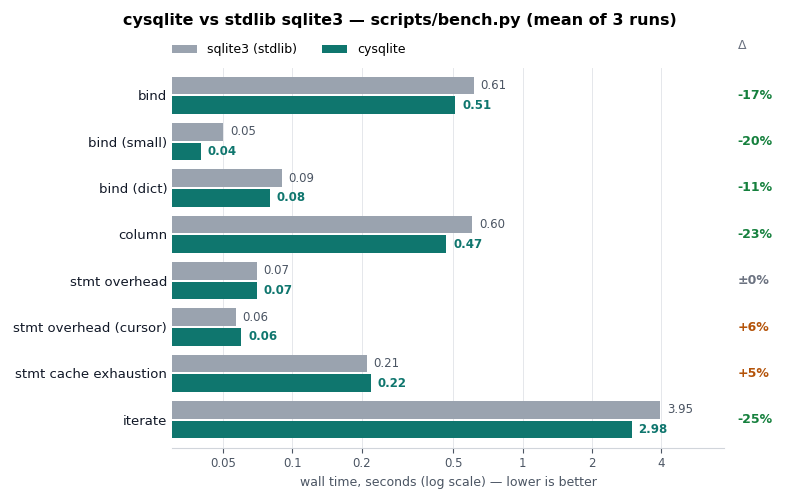
cysqlite - a new sqlite driver
![]()
Back in the spring of 2019, I began working on cysqlite,
a from-scratch DB-API compatible SQLite driver. I intended one day to use it as
a replacement for pysqlite3. Seven years later, the project is ready. It provides an API and performance similar to the standard library sqlite3 module, with many additional features.
Ghost in the Shell: my AI Experiment
A man's at odds to know his mind cause his mind is aught he has to know it with. He can know his heart, but he dont want to. Rightly so. Best not to look in there. It aint the heart of a creature that is bound in the way that God has set for it. You can find meanness in the least of creatures, but when God made man the devil was at his elbow. A creature that can do anything. Make a machine. And a machine to make the machine. An evil that can run itself a thousand years, no need to tend it.
This isn't a post about the machines, though. It is always the human builder that comes first and last.
Asyncio Finally Got Peewee

I feel that it is high time that Peewee had an assyncio story. I've avoided this for years, but asyncio is not going anywhere. Peewee remains a synchronous ORM, but in order to work with the ever-widening sphere of async-first web frameworks and database drivers, it was time to come up with a plan.
AsyncIO

I'd like to put forth my current thinking about asyncio. I hope this will answer some of the questions I've received as to whether Peewee will one day support asyncio, but moreso I hope it will encourage some readers (especially in the web development crowd) to question whether asyncio is appropriate for their project, and if so, look into alternatives like gevent.