Querying the top item by group with peewee ORM
In this post I'd like to share some techniques for querying the top item by group using the Peewee ORM. For example,
- List the most recent tweet by each of my followers.
- List the highest severity bug for each of my open source projects.
- List the latest story in each section of a news site.
This is a common task, but one that can be a little tricky to implement in a single SQL query. To add a twist, we won't use window functions or other special SQL constructs, since they aren't supported by SQLite. If you're interested in finding the top N items per group, check out this follow-up post.
For the purposes of this post, let's take a look at a concrete instance of this problem. Suppose we want to display a list of users and their most-recent post. Here are some basic models, where a User can have 0 or more Posts:
import datetime
from peewee import *
db = SqliteDatabase(':memory:')
class BaseModel(Model):
class Meta:
database = db
class User(BaseModel):
username = CharField(unique=True)
class Post(BaseModel):
user = ForeignKeyField(User, related_name='posts')
content = TextField()
timestamp = DateTimeField(
default=datetime.datetime.now,
index=True)
The naive implementation
The simplest way to implement this is by executing an additional query for each User. To do this in O(n) queries, we might write:
for user in User.select().order_by(User.username):
recent_post = user.posts.order_by(Post.timestamp.desc()).get()
print user.username, recent_post.content
While this works fine for small applications and small data-sets, as your app or data grows those extra queries can really add up. Additionally, if your database is accessed over a network, you want to reduce the number of queries because each query incurs an additional penalty for network latency.
Single query solutions
When I think about trying to express this problem as a single query, there are a couple of different approaches that seem likely to work:
- Use
MAX()to find the maximum post timestamp for a user, then compare post timestamps to that user's max. - Use
NOT EXISTSto find the newest post by excluding all older posts. - Use a self-join and join predicates to ensure the associated post has the largest timestamp for the given user.
In this post we'll explore these potential solutions, see how they work, and compare their overall performance.
Using MAX()
Using MAX(), our goal is to select all the columns from Post and User, group the rows together by the user who made the post, then filter the grouped results such that we only return rows where the post's timestamp equals the max observed timestamp for that user. Of all the queries, this one is the shortest and easiest to understand:
query = (Post
.select(Post, User)
.join(User)
.group_by(Post.user)
.having(Post.timestamp == fn.MAX(Post.timestamp)))
This query translates into the following SQL:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
GROUP BY t1.user_id
HAVING (t1.timestamp = MAX(t1.timestamp))
Unfortunately, Postgresql will not allow us to execute this query, since we've selected columns that are not present in the GROUP BY clause. Let's rewrite this so that we're performing the aggregate in a non-correlated subquery. When we evaluate the outer query, we'll get all the posts, and then throw out the ones that don't correspond to a user/max from the subquery.
# When referencing a table multiple times, we'll call Model.alias() to create
# a secondary reference to the table.
PostAlias = Post.alias()
# Create a subquery that will calculate the maximum Post timestamp for each
# user.
subquery = (PostAlias
.select(
PostAlias.user,
fn.MAX(PostAlias.timestamp).alias('max_ts'))
.group_by(PostAlias.user)
.alias('post_max_subquery'))
# Query for posts and join using the subquery to match the post's user
# and timestamp.
query = (Post
.select(Post, User)
.join(User)
.switch(Post)
.join(subquery, on=(
(Post.timestamp == subquery.c.max_ts) &
(Post.user == subquery.c.user_id))))
This query translates into the following SQL:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
INNER JOIN (
SELECT t4.user_id, MAX(t4.timestamp) AS max_ts
FROM post AS t4
GROUP BY t4.user_id
) AS sq ON (
(t1.timestamp = sq.max_ts) AND
(t1.user_id = sq.user_id))
Using a self-join
In the previous examples we calculated the maximum timestamp separately, then joined the Post by matching it up against the calculated max value. What if we could skip this separate calculation and instead specify a join predicate that would ensure we only select the Post with the maximum timestamp? By doing a self-join on Post, we could ensure that the post we select has, for the given user, the highest timestamp. Let's see how that looks:
# We are doing a self-join, so we will need a second reference to the
# Post table.
PostAlias = Post.alias()
query = (Post
.select(Post, User)
.join(User)
.switch(Post)
.join(PostAlias, JOIN_LEFT_OUTER, on=(
(PostAlias.user == User.id) &
(Post.timestamp < PostAlias.timestamp)))
.where(PostAlias.id.is_null()))
Take a look at that for a moment and it should hopefully make sense. The idea is that we're finding the Post that has no other Post with a greater timestamp. The corresponding SQL is:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
LEFT OUTER JOIN post AS t3 ON (
(t3.user_id = t2.id) AND
(t1.timestamp < t3.timestamp))
WHERE (t3.id IS NULL)
Unlike the previous query, the maximum timestamp is calculated on-the-fly by comparing one post with another.
Using NOT EXISTS
Another way to express the no higher timestamp logic would be to use the SQL NOT EXISTS clause with a subquery. The concept here is similar to the JOIN example above, except that instead of expressing the does not exist logic in the join predicate and where clause, we are using a subquery.
To write this in peewee we will once again alias the Tweet table. We will also the the EXISTS() function. Here is the code:
PostAlias = Post.alias()
# We will be referencing columns from the outer query in the WHERE clause.
subquery = (PostAlias
.select(PostAlias.id)
.where(
(PostAlias.user == User.id) &
(Post.timestamp < PostAlias.timestamp)))
query = (Post
.select(Post, User)
.join(User)
.where(~fn.EXISTS(subquery)))
The corresponding SQL may be a bit easier to read:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
WHERE NOT EXISTS(
SELECT t3.id
FROM post AS t3
WHERE (
(t3.user_id = t2.id) AND
(t1.timestamp < t3.timestamp))
)
I'd assume that the where clause NOT EXISTS function evalutes once per row, leading me to assume it would have O(n2)-type runtime. As we'll see in the next section, SQLite exhibits this type of complexity, but Postgresql is able to optimize the lookup.
Measuring performance
It's a bit difficult to say there's one true way, because depending on the size and shape of the data, one method may be more performant than another. For instance, if there are lots of users and relatively few posts, there will be fewer things to search through when doing JOINs or checking NOT EXISTS subqueries. On the other hand, if there are a larger number of posts per user, the overhead of the NOT EXISTS can overwhelm the query execution time.
To measure the performance I wrote a small script that will populate an in-memory SQLite database with a given number of users and posts-per-user, then time how long it takes to run each type of query. The results varied quite a bit depending on the ratio of posts to users, as you will see. For the control, we can refer to the simple O(n) queries example, which is included in the timings. Also note that there is an index on the Post.timestamp field as well as on the Post.user foreign key.
Below are graphs showing the time it took to execute the queries using the given number of users and posts-per-user. The scale of the graphs is logarithmic to highlight the huge differences in performance between the various queries.


What we can see from the above graphs is that:
- Self-join and NOT EXISTS both exhibited O(n2) run-times with SQLite.
- Simple MAX performed the best across all values, followed closely by Subquery + MAX.
- O(n) performs surprisingly consistently with in-memory SQLite databases.
I ran the same queries (except for simple MAX) against a Postgres database and the results were a bit different. To avoid overloading you with graphs, I'll summarize the results instead.
- Self-join exhibited O(n2) behavior, but the NOT EXISTS query was much more performant. NOT EXISTS performed comparably to using Subquery + MAX.
- O(n) exhibited actual O(n) complexity (unlike SQLite).
Here is the graph of Postgresql with 200 users:
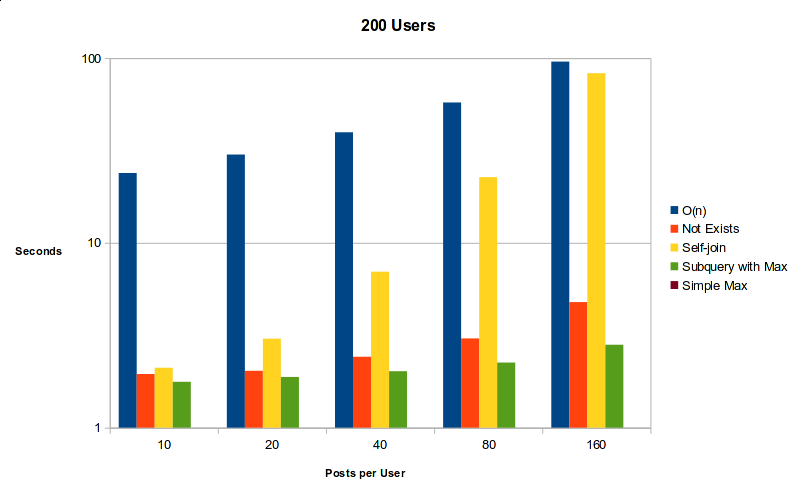
My biggest takeaway is that regardless of the data or the database engine, the best method is to use the subquery + MAX. I believe this is because the subquery, which groups max timestamps by user, can be calculated separately and then set aside for use in the outer query, thereby avoiding O(n2) calculations. Since there's an index on the timestamp field, the outer query can probably be reduced to O(log N) as well.
Thanks for reading
Thanks for taking the time to read this post. Please feel free to make a comment if you have any questions, comments, or suggestions for other ways of expressing this with SQL.
Links
- Querying the top N objects per group with Peewee ORM
- A tour of tagging schemas: many-to-many, bitmaps and more
- Querying tree structures using SQLite and the transitive closure extension
- Window functions by example
- Four ways to join only the first row
- How to select the max row per group
Comments (0)
Commenting has been closed.