Kyoto Tycoon in 2019
![]()
I've been interested in using Kyoto Tycoon for some time. Kyoto Tycoon, successor to Tokyo Tyrant, is a key/value database with a number of desirable features:
- On-disk hash table for fast random access
- On-disk b-tree for ordered collections
- Server supports thousands of concurrent connections
- Embedded lua scripting
- Asynchronous replication, hot backups, update logging
- Exceptional performance
This PDF provides a great description of the database, its performance and implementation. Unfortunately, it is very difficult to find anecdotal information about Kyoto Tycoon (KT) or its companion storage engine Kyoto Cabinet. Debian provides packages for KT, and there are a few questions and answers on StackOverflow, but the absence of a visible user community, and the detritus we typically associate with one, is concerning.
KT seems to crop up in interesting places, however. CloudFlare have a fork in which they've added support for inter-node communication using SSL. It seems like (at one time?) they were using it to globally replicate data from a Postgres DB. Altice Labs, a telecommunications consulting firm, is actively maintaining a separate fork in which they've made a number of small changes (they also have a nice quick-start type guide on configuring KT).
It is a bit easier to find information about Tokyo Tyrant (TT), which was adopted by the Ruby community early in the NoSQL hype cycle. It seems to have largely faded from the picture as of 2010, however, and most of the available information consists of the simplest types of tutorials. From the dates of the articles, client repos, and presentations I've been able uncover, it seems like TT enjoyed a brief surge of developer interest, and everyone had moved on by the time KT was released.
According to db-engines, a site which provides rankings of database popularity, KT is towards the bottom of the heap of the ranked databases. Tokyo Tyrant, its predecessor, fares a little better but it still falls below databases like WiredTiger, Tarantool, FoundationDB and ZODB.
The authors of KT and TT seem to have left the internet behind in the early 2010's, and at some point they replaced their website with a picture of two adorable children and the words: We are rearing children.
Why KT?
At this point I'd like to attempt to answer the question why - why would anyone use this database, abandoned by its authors and, lacking a community of interested or invested users, to all intents and purposes dead?
I see a couple of reasons. KT has a good deal of overlap with the enormously popular database Redis. Some similarities:
- Evented server process capable of handling lots of concurrent connections
- Scriptable via Lua
- Emphasis on speed of database operations (get, set, delete, etc)
Redis has a number of unique features:
- Efficient implementations of various data-structures, such as lists, hashes, sets, sorted sets, etc.
- Massive user community. If there's a bug, someone will find it. Just about everyone has a Redis server somewhere in their stack.
- Responsive author and maintainer, who is personally invested in continuing to improve the project.
- Constantly under pressure to innovate and improve.
KT has some advantages as well:
- Persistence. This is the big one. KT supports larger-than-RAM data-sets. Yes, Redis can periodically dump to disk (RDB), or you can take a performance hit and enable AOF, but persistence is an after-thought and everything needs to be loaded into memory when using Redis.
- Multi-threaded server process. This is the other big one. Redis is single-threaded and, thus, can only occupy a single CPU core. Thanks to its usage of an event-loop, we rarely notice this as the bulk of time is spent in socket i/o, but try running a slow command or Lua script and the entire server will block until it finishes. Besides running on multiple cores, KT should be much more resilient and predictable in the face of occasional slow operations.
- Multiple databases using different storages can be exposed by a single server, for example, I can have an on-disk hash table, an on-disk b-tree, and an in-memory hash table all exposed by the same server process.
- Multi-master replication.
- Compact binary protocol for certain operations.
- Compression (lzo for speed, zlib, or lzma for compactness).
Neither of these lists are exhaustive, but hopefully they provide some insight into the criteria I was interested in when evaluating KT. Furthermore, KT is the culmination of the authors' experience with two other similar databases, QDBM and the Tokyo- database/server. TT and KT were deployed on a high-traffic Japanese social-network and, through trial by fire, may be "finished" in the eyes of the authors.
How fast is it?
I put together a simple benchmarking script that compared the performance of the core key/value operations. For the tests I used the ukt python client I wrote, and the redis-py client (tested with and without hiredis). The results indicate that, even when reading from and writing to disk, KT has a measurable performance advantage.
The benchmark used a single process and a single connection (established ahead of time to avoid the latency of connecting). In a multi-process benchmark (not shown), KT's advantage becomes more pronounced.
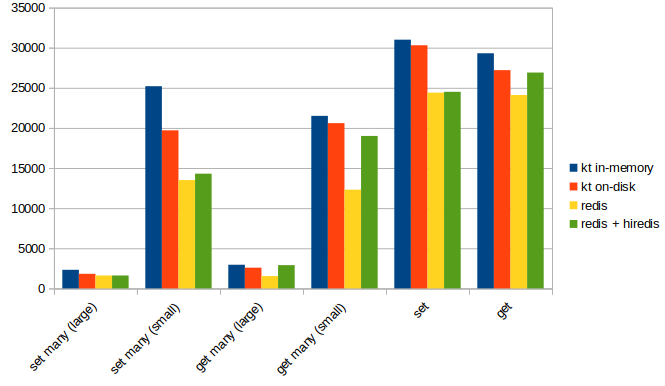
The measurement is operations-per-second, and larger is better.
The source code for the benchmark is available for you to criticize, along with the raw results, which include a handful of additional measurements along with a few additional databases (Tokyo Tyrant, Memcached, e.g.).
As an additional note, KT is a server front-end for Kyoto Cabinet, a lower-level embedded storage engine. For this reason, KT is not really comparable to "pure" storage engines like LevelDB or what-have-you.
Trying it out
I decided to give it a try and have been using it as a cache for a handful of sites I maintain, including this one. Anecdotally, the results have really impressed me, and I plan on continuing to investigate how to better utilize this new piece of technology in my environment. For caching large HTML chunks, I found that gzipping them on the client-side (in a little cache utility module) improved performance around 2x. I also am making use of the speedy bulk get API to efficiently fetch multiple items from the cache, thereby avoiding roundtrip costs. All-in-all it is amazingly fast, simple to manage, and thanks to being persistent, there are no warm-up penalties.
More experimenting
I will certainly be doing some more experimenting with KT. The Lua scripting interface exposes a ton of functionality. The b-tree implementation supports fast prefix matching and range scanning, and would be suitable for secondary indexes, time-series data, etc. I recently watched Rick Houlihan's talk from AWS re:invent, in which he describes sophisticated (completely hacky) key construction schemes to support complex relational data in DynamoDB. Many of these techniques could be applied to KT's B-Tree, which could serve as a fast secondary index.
I hope you found this post interesting. If you'd like to learn more about the Kyoto Cabinet/Tycoon database, here are some useful links:
- Overview of the Kyoto products (pdf)
- Kyoto Tycoon documentation, spec and general info
- Lua APIs exposed by Kyoto Tycoon
- Python client library I wrote, as well as an older version which also supports Tokyo Tyrant.
If you have experience with any of these tools I'd love to hear your war stories...hopefully they're not war stories, though. Success stories, maybe.
Comments (2)
paul | jan 12 2019, at 11:49am
What machine did you run your benchmarks on? The redis results look very low. Is it because of the single connection?
Commenting has been closed.
Daniel Rech | jan 13 2019, at 04:36am
Thank you for the investigation of alternatives to redis.
You mentioned that the maintainers stopped responding so how did you notice it and is there a user community still using it?