Entries tagged with python
Introduction to Redis streams with Python
![]()
Redis 5.0 contains, among lots of fixes and improvements, a new data-type and set of commands for working with persistent, append-only streams.
Redis streams are a complex topic, so I won't be covering all aspects of the APIs, but hopefully after reading this post you'll have a feel for how they work and whether they might be useful in your own projects.
Streams share some superficial similarities with list operations and pub/sub, with some important differences. For instance, task queues are commonly implemented by having multiple workers issue blocking-pop operations on a list. The benefit of this approach is that messages are distributed evenly among the available workers. Downsides, however, are:
- Once a message is read it's effectively "gone forever". If the worker crashes there's no way to tell if the message was processed or needs to be rescheduled. This pushes the responsibility of retrying failed operations onto the consumer.
- Only one client can read a given message. There's no "fan-out".
- No visibility into message state after the message is read.
Similarly, Redis pub/sub can be used to publish a stream of messages to any number of interested consumers. Pub/sub is limited by the fact that it is "fire and forget". There is no history, nor is there any indication that a message has been read.
Streams allow the implementation of more robust message processing workflows, thanks to the following features:
- streams allow messages to be fanned-out to multiple consumers or you can use stateful consumers ("consumer groups") to coordinate message processing among multiple workers.
- message history is preserved and visible to other clients.
- consumer groups support message acknowledgements, claiming stale unacknowledged messages, and introspecting pending messages, ensuring that messages are not lost in the event of an application crash.
- streams support blocking read operations.
The rest of the post will show some examples of working with streams using the walrus Redis library. If you prefer to just read the code, this post is also available as an ipython notebook.
Creating a standalone Python driver for BerkeleyDB's SQLite front-end

In this post I'll provide instructions for building a standalone Python sqlite3-compatible module which is powered by BerkeleyDB. This is possible because BerkeleyDB provides a SQL frontend, which essentially is the SQLite we all know and love with the b-tree code ripped out and replaced with BerkeleyDB.
Misadventures in Python Packaging: Optional C Extensions
I began an unlikely adventure into Python packaging this week when I made what
I thought were some innocuous modifications to the source distribution and
setup.py script for the peewee
database library. Over the course of a day, the setup.py more than doubled in
size and underwent five major revisions as I worked to fix problems arising out
of various differences in users environments. This was tracked in issue #1676,
may it always bear witness to the complexities of Python packaging!
In this post I'll explain what happened, the various things I tried, and how I ended up resolving the issue.
Compiling SQLite for use with Python Applications
The upcoming SQLite 3.25.0 release adds support for one of my favorite SQL language features: window functions. Over the past few years SQLite has released many changes to improve the efficiency of the query planner and virtual machine, plus many extension modules which can provide additional functionality. For example:
- Window function support,
which are available in
trunkand will be included in the next release (3.25.0). - Postgresql-style UPSERT support, which was released on 2018-06-04 (3.24.0).
- FTS5 full-text search extension, which improves on the previous full-text search modules (3.9.0).
- json1 extension, which brings support for JSON to SQLite (3.9.0).
- lsm1 extension and virtual table, while not officially released, is included in the source.
- Eponymous-only virtual tables, or table-valued functions (3.9.0).
- csv virtual table for browsing CSVs directly with SQLite (3.14.0).
Unfortunately, many distributions and operating systems include very old versions of SQLite. When they do include a newer release, typically many of these additional modules are not compiled and are therefore unavailable for use in your Python applications.
In this post I'll walk through obtaining the latest version of SQLite's source code and how to compile it so it includes these exciting features. We'll be doing all of this with the goal of being able to use these features in our Python applications, so we'll also be discussing how to integrate Python with our custom SQLite library.
Kyoto Tycoon and Tokyo Tyrant with Python
![]()
I recently open-sourced a Python library for working with the networked key/value databases Kyoto Tycoon and Tokyo Tyrant. These databases sit atop Kyoto Cabinet and Tokyo Cabinet, respectively, and provide fast DBM implementations.
The Cabinet libraries expose a familiar key/value API backed by a number of different storage options, including persistent hash-tables and b-trees, as well as in-memory variants. A cabinet database can only be accessed by a single process at any given time, though they can be used safely in multi-threaded environments. For this reason, the author created an evented network layer that can expose these storage interfaces to multiple processes. These database servers are Kyoto Tycoon and Tokyo Tyrant, and in addition to providing a fast front-end to the underlying storage engines, they can add features like lua scripting, multi-master replication and LRU cache eviction.
Some scenarios in which you might find these databases useful:
- Memcached or Redis replacement. The LRU eviction provided by Kyoto Tycoon, combined with being scriptable with Lua, and backed with persistent storage, allows these databases to go beyond traditional key/value database roles.
- Time-series and event-logging. The B-Tree storage engine supports fast range scans and ordered key traversal, for rolling-up events, map/reduce workflows, and reporting.
- Full-text search, using the hash storage engine.
- Secondary indexes for external data-stores.
- Document database using lua tables in place of JSON objects.
Features of the kt library:
- Binary protocol support implemented as a C extension.
- Thread-safe and greenlet-safe.
- Simple and memorable APIs.
- Full-featured implementation of the protocols.
- Multiple serialization schemes, including JSON, msgpack and pickle.
If you're interested in trying out these fantastic databases with Python, the documentation for kt can be found here: http://kt-lib.readthedocs.io/en/latest/
Peewee 3.0 released
![]()
On Monday of this week I merged in the 3.0a branch of peewee, a lightweight Python ORM, marking the
official 3.0.0 release
of the project. Today as I'm writing this, the project is at 3.0.9, thanks to
so many helpful people submitting issues and bug reports. Although this was
pretty much a complete rewrite of the 2.x codebase, I have tried to maintain
backwards-compatibility for the public APIs.
In this post I'll discuss a bit about the motivation for the rewrite and some changes to the overall design of the library. If you're thinking about upgrading, check out the changes document and, if you are wondering about any specific APIs, take a spin through the rewritten (and much more thorough) API documentation.
SQLite Database Authorization and Access Control with Python
![]()
The Python standard library sqlite3 driver comes with a barely-documented hook for implementing basic authorization for SQLite databases. Using this hook, it is possible to register a callback that signals, via a return value, what data can be accessed by a connection.
SQLite databases are embedded in the same process as your application, so there is no master server process to act as a gatekeeper for the data stored in your database. Additionally, SQLite database files are readable by anyone with access to the database file itself (unless you are using an encryption library like sqlcipher or sqleet). Restricting access to a SQLite database, once a connection has been opened, is only possible through the use of an authorizer callback.
SQLite provides very granular settings for controlling access, along with two failure modes. Taken together, I think you'll be impressed by the degree of control that is possible.
Write your own miniature Redis with Python
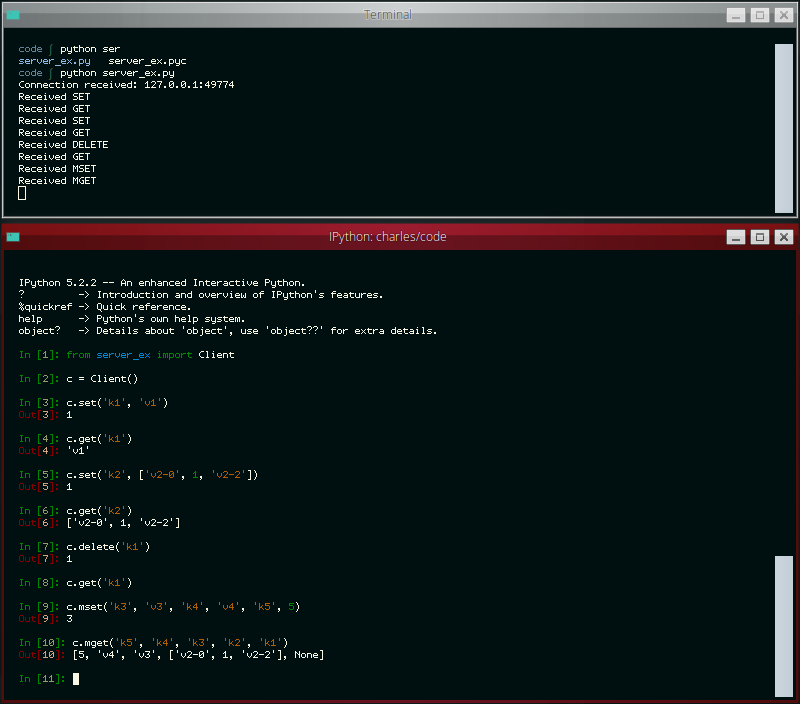
The other day the idea occurred to me that it would be neat to write a simple Redis-like database server. While I've had plenty of experience with WSGI applications, a database server presented a novel challenge and proved to be a nice practical way of learning how to work with sockets in Python. In this post I'll share what I learned along the way.
The goal of my project was to write a simple server that I could use with a task queue project of mine called huey. Huey uses Redis as the default storage engine for tracking enqueued jobs, results of finished jobs, and other things. For the purposes of this post, I've reduced the scope of the original project even further so as not to muddy the waters with code you could very easily write yourself, but if you're curious, you can check out the end result here (documentation).
The server we'll be building will be able to respond to the following commands:
- GET
<key> - SET
<key><value> - DELETE
<key> - FLUSH
- MGET
<key1>...<keyn> - MSET
<key1><value1>...<keyn><valuen>
We'll support the following data-types as well:
- Strings and Binary Data
- Numbers
- NULL
- Arrays (which may be nested)
- Dictionaries (which may be nested)
- Error messages
LSM Key/Value Storage in SQLite3
![]()
Several months ago I was delighted to see a new extension appear in the SQLite source tree. The lsm1 extension is based on the LSM key/value database developed as an experimental storage engine for the now-defunct SQLite4 project. Since development has stopped on SQLite4 for the forseeable future, I was happy to see this technology being folded into SQLite3 and was curious to see what the SQLite developers had in mind for this library.
The SQLite4 LSM captured my interest several years ago as it seemed like a viable alternative to some of the other embedded key/value databases floating around (LevelDB, BerkeleyDB, etc), and I went so far as to write a set of Python bindings for the library. As a storage engine, it seems to offer stable performance, with fast reads of key ranges and fast-ish writes, though random reads may be slower than the usual SQLite3 btree. Like SQLite3, the LSM database supports a single-writer/multiple-reader transactional concurrency model, as well as nested transaction support.
The LSM implementation in SQLite3 is essentially the same as that in SQLite4, plus some additional bugfixes and performance improvements. Crucially, the SQLite3 implementation comes with a standalone extension that exposes the storage engine as a virtual table. The rest of this post will deal with the virtual table, its implementation, and how to use it.
Ditching the Task Queue for Gevent
Task queues are frequently deployed alongside websites to do background processing outside the normal request/response cycle. In the past I've used them for things like sending emails, generating thumbnails, warming caches, or periodically fetching remote resources. By pushing that work out of the request/response cycle, you can increase the throughput (and responsiveness) of your web application.
Depending on your workload, though, it may be possible to move your task processing into the same process as your web server. In this post I'll describe how I did just that using gevent, though the technique would probably work well with a number of different WSGI servers.