Entries tagged with python
Going Fast with SQLite and Python
![]()
In this post I'd like to share with you some techniques for effectively working with SQLite using Python. SQLite is a capable library, providing an in-process relational database for efficient storage of small-to-medium-sized data sets. It supports most of the common features of SQL with few exceptions. Best of all, most Python users do not need to install anything to get started working with SQLite, as the standard library in most distributions ships with the sqlite3 module.
Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.
Optimistic locking in Peewee ORM

In this post I'll share a simple code snippet you can use to perform optimistic locking when updating model instances. I've intentionally avoided providing an implementation for this in peewee, because I don't believe it will be easy to find a one-size-fits-all approach to versioning and conflict resolution. I've updated the documentation to include the sample implementation provided here, however.
Suffering for fashion: a glimpse into my Linux theming toolchain

My desktop at the time of writing.
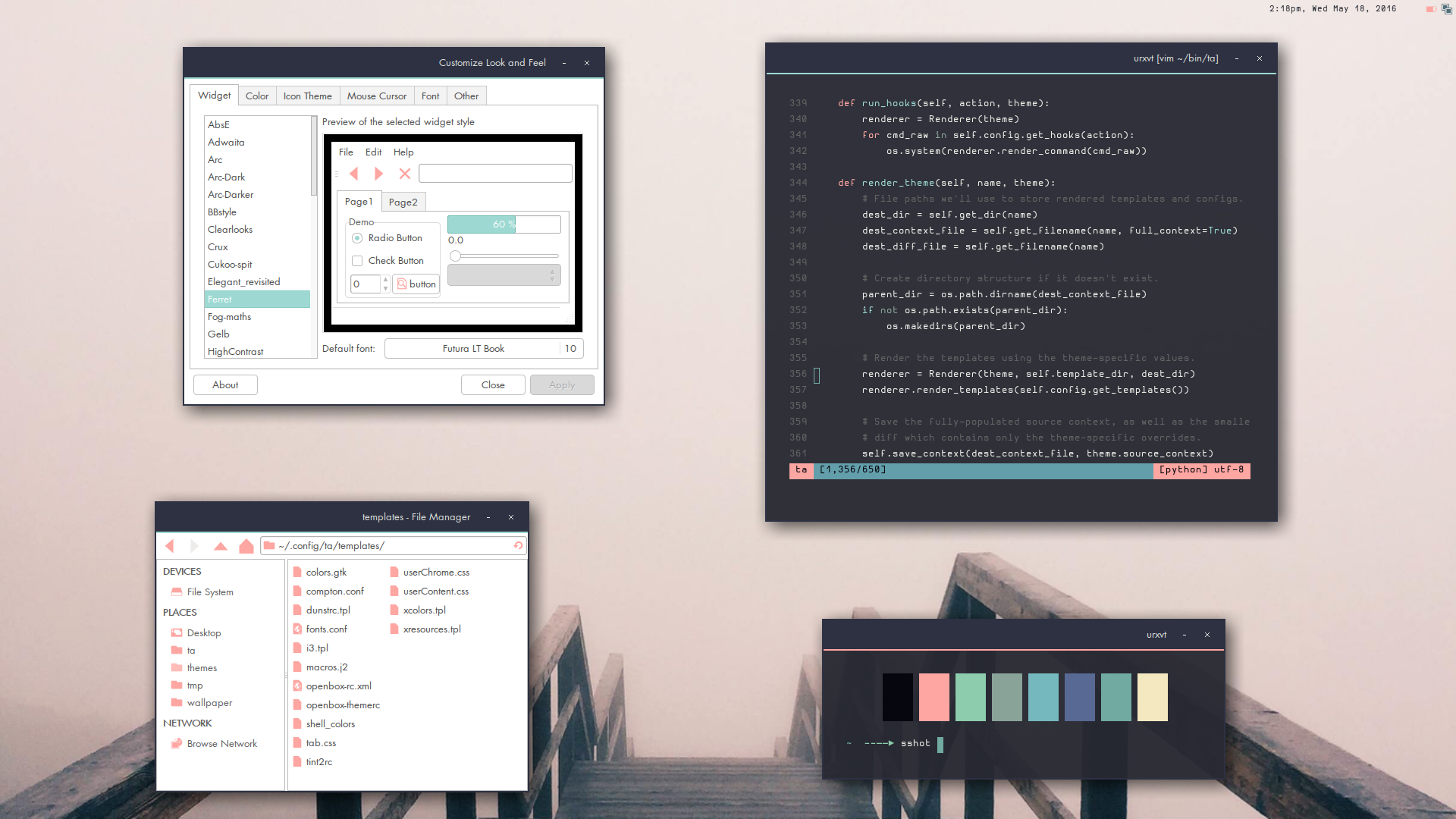
Here it is a couple months later.
It's been over 2 years since I wrote about the tooling I use to theme my desktop, so I thought I'd post about my current scripts...
"For Humans" makes me cringe

When Kenneth Reitz created the requests library, the Python community rushed to embrace the project, as it provided (finally) a clean, sane API for making HTTP requests. He subtitled his project "Python HTTP Requests for Humans", referring, I suppose, to the fact that his API provided developer-friendly APIs. If naming things "for humans" had stopped there, that would have been fine with me, but instead there's been a steady stream of new projects describing themselves as being "For Humans" and I have issues with that.
Five reasons you should use SQLite in 2016
![]()
If you haven't heard, SQLite is an amazing database capable of doing real work in real production environments. In this post, I'll outline 5 reasons why I think you should use SQLite in 2016.
Announcing sophy: fast Python bindings for Sophia Database
![]()
Sophia is a powerful key/value database with loads of features packed into a simple C API. In order to use this database in some upcoming projects I've got planned, I decided to write some Python bindings and the result is sophy. In this post, I'll describe the features of Sophia database, and then show example code using sophy, the Python wrapper.
Here is an overview of the features of the Sophia database:
- Append-only MVCC database
- ACID transactions
- Consistent cursors
- Compression
- Ordered key/value store
- Range searches
- Prefix searches
SQLite Table-Valued Functions with Python
One of the benefits of running an embedded database like SQLite is that you can configure SQLite to call into your application's code. SQLite provides APIs that allow you to create your own scalar functions, aggregate functions, collations, and even your own virtual tables. In this post I'll describe how I used the virtual table APIs to expose a nice API for creating table-valued (or, multi-value) functions in Python. The project is called sqlite-vtfunc and is hosted on GitHub. If you use Peewee, an equivalent implementation is included in the Peewee SQLite extensions.
Using the SQLite JSON1 and FTS5 Extensions with Python
Back in September, word started getting around trendy programming circles about a new file that had appeared in the SQLite fossil repo named json1.c. I originally wrote up a post that contained some gross hacks in order to get pysqlite to compile and work with the new json1 extension. With the release of SQLite 3.9.0, those hacks are no longer necessary.
SQLite 3.9.0 is a fantastic release. In addition to the much anticipated json1 extension, there is a new version of the full-text search extension called fts5. fts5 improves performance of complex search queries and provides an out-of-the-box BM25 ranking implementation. You can also boost the significance of particular fields in the ranking. I suggest you check out the release notes for the full list of enhancements
This post will describe how to compile SQLite with support for json1 and fts5. We'll use the new SQLite library to compile a python driver so we can use the new features from python. Because I really like pysqlite and apsw, I've included instructions for building both of them. Finally, we'll use peewee ORM to run queries using the json1 and fts5 extensions.
Using SQLite4's LSM Storage Engine as a Stand-alone NoSQL Database with Python

SQLite and Key/Value databases are two of my favorite topics to blog about. Today I get to write about both, because in this post I will be demonstrating a Python wrapper for SQLite4's log-structured merge-tree (LSM) key/value store.
I don't actively follow SQLite's releases, but the recent release of SQLite 3.8.11 drew quite a bit of attention as the release notes described massive performance improvements over 3.8.0. While reading the release notes I happened to see a blurb about a new, experimental full-text search extension, and all this got me to wondering what was going on with SQLite4.
As I was reading about SQLite4, I saw that one of the design goals was to provide an interface for pluggable storage engines. At the time I'm writing this, SQLite4 has two built-in storage backends, one of which is an LSM key/value store. Over the past month or two I've been having fun with Cython, writing Python wrappers for the embedded key/value stores UnQLite and Vedis. I figured it would be cool to use Cython to write a Python interface for SQLite4's LSM storage engine.
After pulling down the SQLite4 source code and reading through the LSM header file (it's very small!), I started coding and the result is python-lsm-db (docs).
Read the rest of the post for examples of how to use the library.