Entries tagged with peewee
Peewee 4: Async, JSON, Eager-Loading and Types

If you listen real close you can hear the type whispers in there.
Peewee 4.x is a picture, in code, of me eating my hat. We got async
and are shipping a significantly better type whispering
stub based on typeshed's original. Beyond those, I've added a core JSONField
which exposes a nice cross-backend API for working with JSON data, and a new
declarative API for eager-loading relations.
Read on for the details.
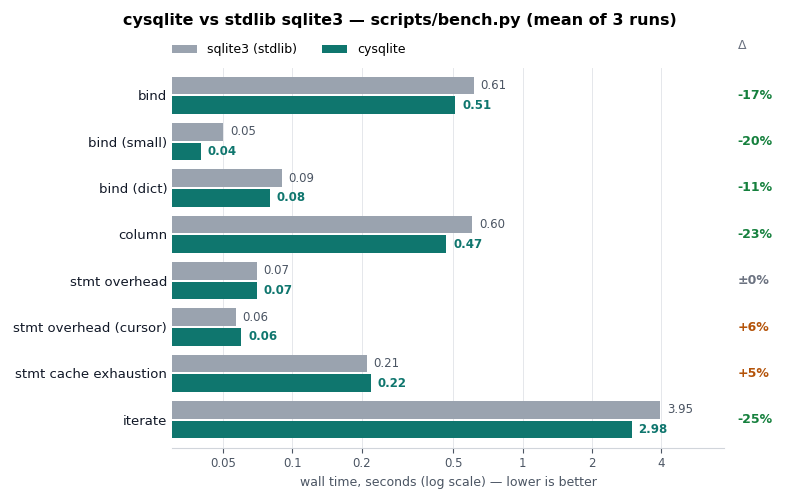
cysqlite - a new sqlite driver
![]()
Back in the spring of 2019, I began working on cysqlite,
a from-scratch DB-API compatible SQLite driver. I intended one day to use it as
a replacement for pysqlite3. Seven years later, the project is ready. It provides an API and performance similar to the standard library sqlite3 module, with many additional features.
Asyncio Finally Got Peewee

I feel that it is high time that Peewee had an assyncio story. I've avoided this for years, but asyncio is not going anywhere. Peewee remains a synchronous ORM, but in order to work with the ever-widening sphere of async-first web frameworks and database drivers, it was time to come up with a plan.
Peewee now supports CockroachDB

I'm pleased to announce that Peewee now supports CockroachDB (CRDB), the distributed, horizontally-scalable SQL database. I'm excited about this release, because it's now quite easy to get up-and-running with a robust SQL database that can scale out with minimal effort (documentation).
Here is how you configure a CockroachDatabase instance:
from playhouse.cockroachdb import CockroachDatabase
db = CockroachDatabase('my_app', user='root', host='10.1.0.8', port=26257)
CRDB conveniently provides a very similar SQL dialect to Postgres, which has been
well-supported in Peewee for many years, allowing you to use features like jsonb
and arrays,
in addition to the regular complement of field-types. Additionally, CRDB speaks
the same wire-protocol as Postgres, so it works out-of-the-box using the
popular psycopg2 driver.
Misadventures in Python Packaging: Optional C Extensions
I began an unlikely adventure into Python packaging this week when I made what
I thought were some innocuous modifications to the source distribution and
setup.py script for the peewee
database library. Over the course of a day, the setup.py more than doubled in
size and underwent five major revisions as I worked to fix problems arising out
of various differences in users environments. This was tracked in issue #1676,
may it always bear witness to the complexities of Python packaging!
In this post I'll explain what happened, the various things I tried, and how I ended up resolving the issue.
Peewee 3.0 released
![]()
On Monday of this week I merged in the 3.0a branch of peewee, a lightweight Python ORM, marking the
official 3.0.0 release
of the project. Today as I'm writing this, the project is at 3.0.9, thanks to
so many helpful people submitting issues and bug reports. Although this was
pretty much a complete rewrite of the 2.x codebase, I have tried to maintain
backwards-compatibility for the public APIs.
In this post I'll discuss a bit about the motivation for the rewrite and some changes to the overall design of the library. If you're thinking about upgrading, check out the changes document and, if you are wondering about any specific APIs, take a spin through the rewritten (and much more thorough) API documentation.
Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.
Optimistic locking in Peewee ORM

In this post I'll share a simple code snippet you can use to perform optimistic locking when updating model instances. I've intentionally avoided providing an implementation for this in peewee, because I don't believe it will be easy to find a one-size-fits-all approach to versioning and conflict resolution. I've updated the documentation to include the sample implementation provided here, however.
Using the SQLite JSON1 and FTS5 Extensions with Python
Back in September, word started getting around trendy programming circles about a new file that had appeared in the SQLite fossil repo named json1.c. I originally wrote up a post that contained some gross hacks in order to get pysqlite to compile and work with the new json1 extension. With the release of SQLite 3.9.0, those hacks are no longer necessary.
SQLite 3.9.0 is a fantastic release. In addition to the much anticipated json1 extension, there is a new version of the full-text search extension called fts5. fts5 improves performance of complex search queries and provides an out-of-the-box BM25 ranking implementation. You can also boost the significance of particular fields in the ranking. I suggest you check out the release notes for the full list of enhancements
This post will describe how to compile SQLite with support for json1 and fts5. We'll use the new SQLite library to compile a python driver so we can use the new features from python. Because I really like pysqlite and apsw, I've included instructions for building both of them. Finally, we'll use peewee ORM to run queries using the json1 and fts5 extensions.
A Tour of Tagging Schemas: Many-to-many, Bitmaps and More

In this post I'll describe how to implement tagging with a relational database. What I mean by tagging are those little labels you see at the top of this blog post, which indicate how I've chosen to categorize the content. There are many ways to solve this problem, and I'll try to describe some of the more popular methods, as well as one unconventional approach using bitmaps. In each section I'll describe the database schema, try to list the benefits and drawbacks, and present example queries. I will use Peewee ORM for the example code, but hopefully these examples will easily translate to your tool-of-choice.