Entries tagged with sqlite
cysqlite - a new sqlite driver
![]()
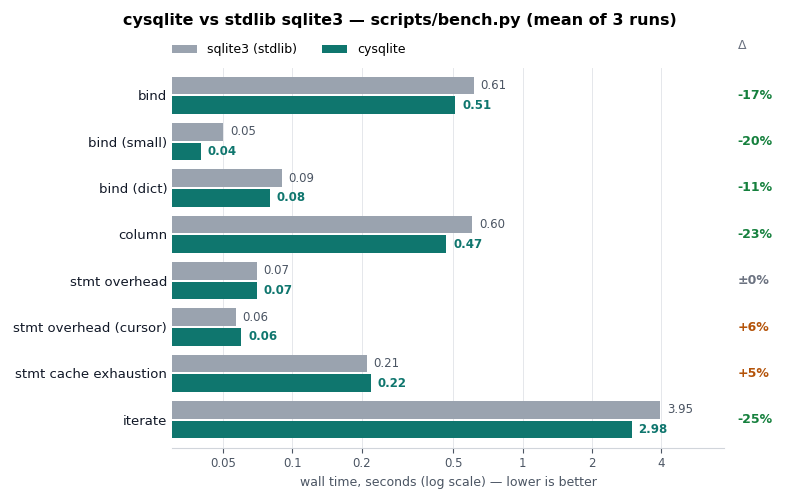
Back in the spring of 2019, I began working on cysqlite,
a from-scratch DB-API compatible SQLite driver. I intended one day to use it as
a replacement for pysqlite3. Seven years later, the project is ready. It provides an API and performance similar to the standard library sqlite3 module, with many additional features.
ucache, a lightweight caching library for python
![]()
I recently wrote about Kyoto Tycoon (KT), a fast key/value database server. KT databases may be ordered (B-Tree / red-black tree) or unordered (hash table), and persistent or stored completely in-memory. Among other things, I'm using KT's hash database as a cache for things like HTML fragments, RSS feed data, etc. KT supports automatic, time-based expiration, so using it as a cache is a natural fit.
Besides using KT as a cache, in the past I have also used Redis and Sqlite. So I've released a small library I'm calling ucache which can be used with these storage backends and has a couple nice features. I will likely flesh it out and add support for additional storages as I find time to work on it.
Creating a standalone Python driver for BerkeleyDB's SQLite front-end

In this post I'll provide instructions for building a standalone Python sqlite3-compatible module which is powered by BerkeleyDB. This is possible because BerkeleyDB provides a SQL frontend, which essentially is the SQLite we all know and love with the b-tree code ripped out and replaced with BerkeleyDB.
Compiling SQLite for use with Python Applications
The upcoming SQLite 3.25.0 release adds support for one of my favorite SQL language features: window functions. Over the past few years SQLite has released many changes to improve the efficiency of the query planner and virtual machine, plus many extension modules which can provide additional functionality. For example:
- Window function support,
which are available in
trunkand will be included in the next release (3.25.0). - Postgresql-style UPSERT support, which was released on 2018-06-04 (3.24.0).
- FTS5 full-text search extension, which improves on the previous full-text search modules (3.9.0).
- json1 extension, which brings support for JSON to SQLite (3.9.0).
- lsm1 extension and virtual table, while not officially released, is included in the source.
- Eponymous-only virtual tables, or table-valued functions (3.9.0).
- csv virtual table for browsing CSVs directly with SQLite (3.14.0).
Unfortunately, many distributions and operating systems include very old versions of SQLite. When they do include a newer release, typically many of these additional modules are not compiled and are therefore unavailable for use in your Python applications.
In this post I'll walk through obtaining the latest version of SQLite's source code and how to compile it so it includes these exciting features. We'll be doing all of this with the goal of being able to use these features in our Python applications, so we'll also be discussing how to integrate Python with our custom SQLite library.
SQLite Database Authorization and Access Control with Python
![]()
The Python standard library sqlite3 driver comes with a barely-documented hook for implementing basic authorization for SQLite databases. Using this hook, it is possible to register a callback that signals, via a return value, what data can be accessed by a connection.
SQLite databases are embedded in the same process as your application, so there is no master server process to act as a gatekeeper for the data stored in your database. Additionally, SQLite database files are readable by anyone with access to the database file itself (unless you are using an encryption library like sqlcipher or sqleet). Restricting access to a SQLite database, once a connection has been opened, is only possible through the use of an authorizer callback.
SQLite provides very granular settings for controlling access, along with two failure modes. Taken together, I think you'll be impressed by the degree of control that is possible.
LSM Key/Value Storage in SQLite3
![]()
Several months ago I was delighted to see a new extension appear in the SQLite source tree. The lsm1 extension is based on the LSM key/value database developed as an experimental storage engine for the now-defunct SQLite4 project. Since development has stopped on SQLite4 for the forseeable future, I was happy to see this technology being folded into SQLite3 and was curious to see what the SQLite developers had in mind for this library.
The SQLite4 LSM captured my interest several years ago as it seemed like a viable alternative to some of the other embedded key/value databases floating around (LevelDB, BerkeleyDB, etc), and I went so far as to write a set of Python bindings for the library. As a storage engine, it seems to offer stable performance, with fast reads of key ranges and fast-ish writes, though random reads may be slower than the usual SQLite3 btree. Like SQLite3, the LSM database supports a single-writer/multiple-reader transactional concurrency model, as well as nested transaction support.
The LSM implementation in SQLite3 is essentially the same as that in SQLite4, plus some additional bugfixes and performance improvements. Crucially, the SQLite3 implementation comes with a standalone extension that exposes the storage engine as a virtual table. The rest of this post will deal with the virtual table, its implementation, and how to use it.
Going Fast with SQLite and Python
![]()
In this post I'd like to share with you some techniques for effectively working with SQLite using Python. SQLite is a capable library, providing an in-process relational database for efficient storage of small-to-medium-sized data sets. It supports most of the common features of SQL with few exceptions. Best of all, most Python users do not need to install anything to get started working with SQLite, as the standard library in most distributions ships with the sqlite3 module.
Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.
Five reasons you should use SQLite in 2016
![]()
If you haven't heard, SQLite is an amazing database capable of doing real work in real production environments. In this post, I'll outline 5 reasons why I think you should use SQLite in 2016.
SQLite Table-Valued Functions with Python
One of the benefits of running an embedded database like SQLite is that you can configure SQLite to call into your application's code. SQLite provides APIs that allow you to create your own scalar functions, aggregate functions, collations, and even your own virtual tables. In this post I'll describe how I used the virtual table APIs to expose a nice API for creating table-valued (or, multi-value) functions in Python. The project is called sqlite-vtfunc and is hosted on GitHub. If you use Peewee, an equivalent implementation is included in the Peewee SQLite extensions.