Entries tagged with sqlite
Using SQLite4's LSM Storage Engine as a Stand-alone NoSQL Database with Python

SQLite and Key/Value databases are two of my favorite topics to blog about. Today I get to write about both, because in this post I will be demonstrating a Python wrapper for SQLite4's log-structured merge-tree (LSM) key/value store.
I don't actively follow SQLite's releases, but the recent release of SQLite 3.8.11 drew quite a bit of attention as the release notes described massive performance improvements over 3.8.0. While reading the release notes I happened to see a blurb about a new, experimental full-text search extension, and all this got me to wondering what was going on with SQLite4.
As I was reading about SQLite4, I saw that one of the design goals was to provide an interface for pluggable storage engines. At the time I'm writing this, SQLite4 has two built-in storage backends, one of which is an LSM key/value store. Over the past month or two I've been having fun with Cython, writing Python wrappers for the embedded key/value stores UnQLite and Vedis. I figured it would be cool to use Cython to write a Python interface for SQLite4's LSM storage engine.
After pulling down the SQLite4 source code and reading through the LSM header file (it's very small!), I started coding and the result is python-lsm-db (docs).
Read the rest of the post for examples of how to use the library.
Meet Scout, a Search Server Powered by SQLite

In my continuing adventures with SQLite, I had the idea of writing a RESTful search server utilizing SQLite's full-text search extension. You might think of it as a poor man's ElasticSearch.
So what is this project? Well, the idea I had was that instead of building out separate search implementations for my various projects, I would build a single lightweight search service I could use everywhere. I really like SQLite (and have previously blogged about using SQLite's full-text search with Python), and the full-text search extension is quite good, so it didn't require much imagination to take the next leap and expose it as a web-service.
Read on for more details.
Extending SQLite with Python

SQLite is an embedded database, which means that instead of running as a separate server process, the actual database engine resides within the application. This makes it possible for the database to call directly into the application when it would be beneficial to add some low-level, application-specific functionality. SQLite provides numerous hooks for inserting user code and callbacks, and, through virtual tables, it is even possible to construct a completely user-defined table. By extending the SQL language with Python, it is often possible to express things more elegantly than if we were to perform calculations after the fact.
In this post I'll describe how to extend SQLite with Python, adding functions and aggregates that will be callable directly from any SQL queries you execute. We'll wrap up by looking at SQLite's virtual table mechanism and seeing how to expose a SQL interface over external data sources.
Querying Tree Structures in SQLite using Python and the Transitive Closure Extension

I recently read a good write-up on tree structures in PostgreSQL. Hierarchical data is notoriously tricky to model in a relational database, and a variety of techniques have grown out of developers' attempts to optimize for certain types of queries.
In his post, Graeme describes several approaches to modeling trees, including:
- Adjancency models, in which each node in the tree contains a foreign key to its parent row.
- Materialized path model, in which each node stores its ancestral path in a denormalized column. Typically the path is stored as a string separated by a delimiter, e.g. "{root id}.{child id}.{grandchild id}".
- Nested sets, in which each node defines an interval that encompasses a range of child nodes.
- PostgreSQL arrays, in which the materialized path is stored in an array, and general inverted indexes are used to efficiently query the path.
In the comments, some users pointed out that the ltree extension could also be used to efficiently store and query materialized paths. LTrees support two powerful query languages (lquery and ltxtquery) for pattern-matching LTree labels and performing full-text searches on labels.
One technique that was not discussed in Graeme's post was the use of closure tables. A closure table is a many-to-many junction table storing all relationships between nodes in a tree. It is related to the adjacency model, in that each database row still stores a reference to its parent row. The closure table gets its name from the additional table, which stores each combination of ancestor/child nodes.
Web-based SQLite Database Browser, powered by Flask and Peewee

For the past week or two I've been spending some of my spare time working on a web-based SQLite database browser. I thought this would be a useful project, because I've switched all my personal projects over to SQLite and foresee using it for pretty much everything. It also dovetailed with some work I'd been doing lately on peewee regarding reflection and code generation. So it seemed like some pretty good bang/buck, especially given my perception that there weren't many SQLite browsers out there (it turns out there are quite a few, however). I'm sharing it in the hopes that other devs (and non-devs?) find it useful.
Dear Diary, an Encrypted Command-Line Diary with Python
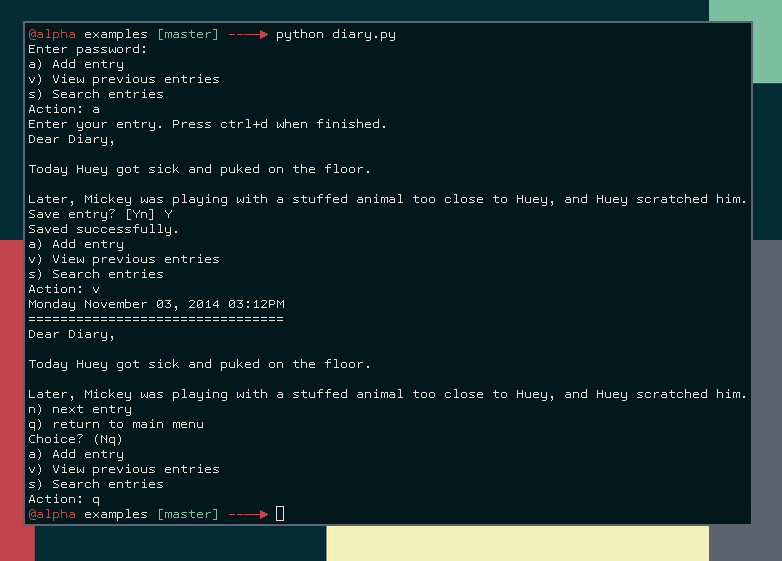
In my last post, I wrote about how to work with encrypted SQLite databases with Python. As an example application of these libraries, I showed some code fragments for a fictional diary program. Because I was thinking the examples directory of the peewee repo was looking a little thin, I decided to flesh out the diary program and include it as an example.
In this post, I'll go over the diary code in the hopes that you may find it interesting or useful. The code shows how to use the peewee SQLCipher extension. I've also implemented a simple command-line menu loop. All told, the code is less than 100 lines!
Encrypted SQLite Databases with Python and SQLCipher
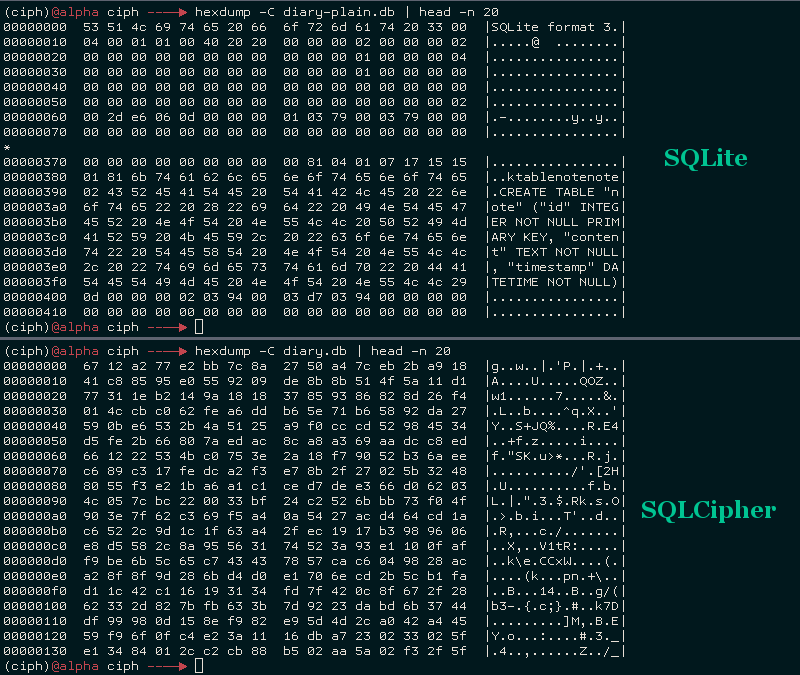
SQLCipher, created by Zetetic, is an open-source library that provides transparent 256-bit AES encryption for your SQLite databases. SQLCipher is used by a large number of organizations, including Nasa, SalesForce, Xerox and more. The project is open-source and BSD licensed, and there are open-source python bindings.
A GitHub user known as The Dod was kind enough to contribute a sqlcipher playhouse module, making it a snap to use Peewee with SQLCipher.
In this post, I'll show how to compile SQLCipher and the sqlcipher3 python bindings, then use peewee ORM to work with an encrypted SQLite database.
SQLite: Small. Fast. Reliable. Choose any three.
![]()
SQLite is a fantastic database and in this post I'd like to explain why I think that, for many scenarios, SQLite is actually a great choice. I hope to also clear up some common misconceptions about SQLite.
Using SQLite Full-Text Search with Python

In this post I will show how to use SQLite full-text search with Python (and a lot of help from peewee ORM). We will see how to index content for searching, and how to order search results using two ranking algorithms.
Last week I migrated my site from Postgresql to SQLite. I had been using Redis to power my site's search, but since SQLite has an awesome full-text search extension, I decided to give it a try. I am really pleased with the results, and being able to specify boolean search queries is an added plus. Here is a brief overview of the types of search queries SQLite supports:
- Simple phrase: peewee would return all docs containing the word peewee.
- Prefix queries: py* would return docs containing Python, pypi, etc.
- Quoted phrases: "sqlite extension"
NEAR: peewee NEAR sqlite would return docs containing the words peewee and sqlite with no more than10intervening words. You can also specify the max number of intervening words, e.g. peewee NEAR/3 sqlite.AND,OR,NOT: sqlite OR postgresql AND NOT mysql would return docs about high-quality databases (just trollin).
Check out the full post for details on adding full-text search to your project.
Migrating to SQLite
![]()
Small. Fast. Reliable. Choose any three.
I made the decision this week to migrate my personal sites and several other sites I host onto SQLite. Previously almost everything I hosted had been using Postgresql. The move was motivated by a couple factors:
- SQLite is awesome!
- Self-contained: does not require a separate server process
- Data is stored in a single file, simplifying backups
- Excellent Python (and peewee) support
- Full-text search
At times it has seemed to me that there is a tacit agreement within the Flask / Django communities that if you're using SQL you should be using Postgresql. Postgresql is an amazing piece of engineering. I have spent the last five years of my career working exclusively with it, and I am continually impressed by its performance and the constant stream of great new features.
So why change things?
Well, as my list indicates, there are a handful of reasons. But the primary reason was that I wanted something lightweight. I'm running a fairly low-traffic, read-heavy site, so Postgresql was definitely overkill. My blog is deployed on a VPS with very limited resources, so every MB of RAM counts. Additionally, I wasn't using any special Postgresql features so there was nothing holding me back.
(continued...)