Entries tagged with django
The search for the missing link: what lies between SQL and Django's ORM?
I had the opportunity this week to write some fairly interesting SQL queries. I don't write "raw" SQL too often, so it was fun to use that part of my brain (by the way, does it bother anyone else when people call SQL "raw"?). At Counsyl we use Django for pretty much everything so naturally we also use the ORM. Every place I've worked there's a strong bias against using SQL when you've got an ORM on board, which makes sense -- if you choose a tool you should standardize on it if for no other reason than it makes maintenance easier.
So as I was saying, I had some pretty interesting queries to write and I struggled to think how to shoehorn them into Django's ORM. I've already written about some of the shortcomings of Django's ORM so I won't rehash those points. I'll just say that Django fell short and I found myself writing SQL. The queries I was working on joined models from very disparate parts of our codebase. The joins were on values that weren't necessarily foreign keys (think UUIDs) and this is something that Django just doesn't cope with. Additionally I was interested in aggregates on calculated values, and it seems like Django can only do aggregates on a single column.
As I was prototyping, I found several mistakes in my queries and decided to run them in the postgres shell before translating them into my code. I started to think that some of these errors could have been avoided if I could find an abstraction that sat between the ORM and a string of SQL. By leveraging the python interpreter, the obvious syntax errors could have been caught at module import time. By using composable data structures, methods I wrote that used similar table structures could have been more DRY. When I write less code, I think I generally write less bugs as well.
That got me started on my search for the "missing link" between SQL (represented as a string) and Django's ORM.
Structuring flask apps, a how-to for those coming from Django
The other day a friend of mine was trying out flask-peewee and he had some questions about the best way to structure his app to avoid triggering circular imports. For someone new to flask, this can be a bit of a puzzler, especially if you're coming from django which automatically imports your modules. In this post I'll walk through how I like to structure my flask apps to avoid circular imports. In my examples I'll be showing how to use "flask-peewee", but the same technique should be applicable for other flask plugins.
I'll walk through the modules I commonly use in my apps, then show how to tie them all together and provide a single entrypoint into your app.
Shortcomings in the Django ORM and a look at Peewee, a lightweight alternative
In this post I'd like to talk about some of the shortcomings of the Django ORM, the ways peewee approaches things differently, and how this resulted in peewee having an API that is both more consistent and more expressive.
Working around Django's ORM to do interesting things with GFKs
In this post I want to discuss how to work around some of the shortcomings of djangos ORM when dealing with Generic Foreign Keys (GFKs).
At the end of the post I'll show how to work around django's lack of correctly CAST-ing when the generic foreign key is of a different column type than the objects it may point to.
Micawber, a python library for extracting rich content from URLs
![]()
OEmbed is a simple, open API standard for embedding rich content and retrieving content metadata. The way OEmbed works is actually kind of ingenious, because the only things a consumer of the API needs to know are the location of the OEmbed endpoint, and the URL to the piece of content they want to embed.
YouTube, for example, maintains an OEmbed endpoint at youtube.com/oembed. Using the OEmbed endpoint, we can very easily retrieve the HTML for an embedded video player along with metadata about the clip:
GET https://www.youtube.com/oembed?url=https://www.youtube.com/watch?v=nda_OSWeyn8
Response:
{
"provider_url": "https://www.youtube.com/",
"title": "Leprechaun in Mobile, Alabama",
"type": "video",
"html": "<iframe width=\"459\" height=\"344\" src=\"https://www.youtube.com/embed/nda_OSWeyn8?feature=oembed\" frameborder=\"0\" allowfullscreen></iframe>",
"thumbnail_width": 480,
"height": 344,
"width": 459,
"version": "1.0",
"author_name": "botmib",
"thumbnail_height": 360,
"thumbnail_url": "https://i.ytimg.com/vi/nda_OSWeyn8/hqdefault.jpg",
"provider_name": "YouTube",
"author_url": "https://www.youtube.com/user/botmib"
}
The oembed spec defines four types of content along with a number of required attributes for each content type. This makes it a snap for consumers to use a single interface for handling things like:
- youtube videos
- flickr photos
- hulu videos
- slideshare decks
- and many more
Integrating the flask microframework with the peewee ORM
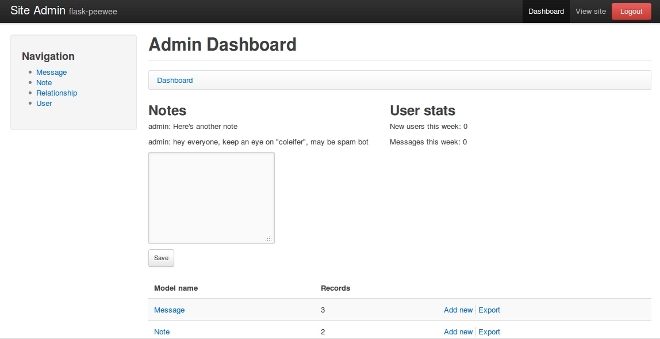
I'd like to write a post about a project I've been working on for the past month or so. I've had a great time working on it and am excited to start putting it to use. The project is called flask-peewee -- it is a set of utilities that bridges the python microframework flask and the lightweight ORM peewee. It is packaged as a flask extension and comes with the following batteries included:
- Admin interface a-la django
- RESTful API toolkit a-la tastypie
- Authentication system
{kind=link}
Connecting anything to anything with Django
I'm writing this post to introduce a new project I've released, django-generic-m2m, which as its name would indicate is a generic ManyToMany implementation for django models. The goal of this project was to provide a uniform API for both creating and querying generically-related content in a flexible manner. One use-case for this project would be creating semantic "tags" between diverse objects in the database.
Peewee, a lightweight Python ORM - Original Post
For the past month or so I've been working on writing my own ORM in Python. The project grew out of a need for a lightweight persistence layer for use in Flask web apps. As I've grown so familiar with the Django ORM over the past year, many of the ideas in Peewee are analagous to the concepts in Django. My goal from the beginning has been to keep the implementation simple without sacrificing functionality, and to ultimately create something hackable that others might be able to read and contribute to.
Django Patterns: Model Inheritance
This post discusses the two flavors of model inheritance supported by Django, some of their use-cases as well as some potential gotchas.
Django Patterns: Pluggable Backends
As the first installment in a series on common patterns in Django development, I'd like to discuss the Pluggable Backend pattern. The pattern addresses the common problem of providing extensible support for multiple implementations of a lower level function, be it caching, database querying, etc.