Querying the top N objects per group with Peewee ORM

This post is a follow-up to my post about querying the top related item by group. In this post we'll go over ways to retrieve the top N related objects by group using the Peewee ORM. I've also presented the SQL and the underlying ideas behind the queries, so you can translate them to whatever ORM / query layer you are using.
Retrieving the top N per group is a pretty common task, for example:
- Display my followers and their 10 most recent tweets.
- In each of my inboxes, list the 5 most recent unread messages.
- List the sections of the news site and the three latest stories in each.
- List the five best sales in each department.
In this post we'll discuss the following types of solutions:
- Solutions involving
COUNT() - Solutions involving
LIMIT - Window functions
- Postgresql lateral joins
For the purposes of this post, and for continuity with last week's post, the examples will focus on displaying a list of users and their three most-recent posts. Here are the database models we'll be using:
import datetime
from peewee import *
db = SqliteDatabase(':memory:')
class BaseModel(Model):
class Meta:
database = db
class User(BaseModel):
username = CharField(unique=True)
class Post(BaseModel):
user = ForeignKeyField(User, related_name='posts')
content = TextField()
timestamp = DateTimeField(
default=datetime.datetime.now,
index=True)
The naive implementation
The simplest way to implement this is by executing an additional query for each User. To do this in O(n) queries, we might write:
for user in User.select().order_by(User.username):
recent_posts = user.posts.order_by(Post.timestamp.desc()).limit(3)
print 'Recent posts by', user.username
for post in recent_posts:
print '*', post.content
This approach has the benefit of simplicity, and works fine for smaller applications or situations where the list of users is not very large. Since we have an index on the Post.timestamp and Post.user fields, retrieving the latest posts for a user is quite fast.
As we'll see when we start comparing the execution times of various queries, it may surprise you that with SQLite the naive O(n) approach may actually be a very good choice! However, with a more sophisticated database like Postgresql, or a database that is accessed over a network, the O(n) approach is not likely to be the best choice.
Single query solutions
In the previous post we were focused only on retrieving the single most-recent Post by a given User. Because we only needed one Post, we could use the Max() aggregate and other tricks like NOT EXISTS. The more general most recent N query requires a different approach.
Counting solutions
The first approach I'd like to discuss uses counting to retrieve the most recent posts. Our query will express the following statement:
Get all the posts where there are less than N posts with a higher timestamp.
This is a sort of roundabout way of getting to a solution, but the query is not too complex so I thought it would be a good one to start with. What we will do is use a subquery to determine the number of posts with a higher (more recent) timestamp than the post we are currently examining, and throw out any where that count exceeds N. Here is how we might write it with Peewee:
PostAlias = Post.alias()
# Create a correlated subquery that calculates the number of
# posts with a higher (newer) timestamp than the post we're
# looking at in the outer query.
subquery = (PostAlias
.select(fn.COUNT(PostAlias.id))
.where(
(PostAlias.timestamp >= Post.timestamp) &
(PostAlias.user == Post.user)))
# Wrap the subquery and filter on the count.
query = (Post
.select(Post, User)
.join(User)
.where(subquery <= 3))
The resulting SQL query is:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
WHERE (
SELECT COUNT(t3.id)
FROM post AS t3
WHERE (
(t3.timestamp >= t1.timestamp) AND
(t3.user_id = t1.user_id))
) <= 3
As you might imagine, this query is probably not very efficient since the subquery is correlated and must be calculated separately for each post in the outer query.
Another way we can express similar logic is by doing a self-join on Post and using a combination of join predicates and the SQL HAVING clause to restrict the result set. This query is also fairly simple and will work on both Postgresql and SQLite.
PostAlias = Post.alias()
# Use a self-join and join predicates to count the number of
# newer posts.
query = (Post
.select(Post.id, Post.content, Post.user, User.username)
.join(User)
.switch(Post)
.join(PostAlias, on=(
(PostAlias.user == Post.user) &
(PostAlias.timestamp >= Post.timestamp)))
.group_by(Post.id, Post.content, Post.user, User.username)
.having(fn.COUNT(Post.id) <= 3))
Here is the corresponding SQL query:
SELECT t1.id, t1.user_id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
INNER JOIN post AS t3 ON (
(t3.user_id = t1.user_id) AND
(t3.timestamp >= t1.timestamp))
GROUP BY t1.id, t1.content, t1.user_id, t2.username
HAVING (COUNT(t1.id) <= 3)
Despite the simplicity of the query, the self-join ends up being pretty expensive and gives the query a pretty bad run-time on both SQLite and Postgresql.
I made one final attempt at the COUNT approach based on some SQL I saw on StackOverflow. This query is similar to the previous query, in that we are using a self-join and HAVING clause to find the most recent posts per user. The difference is that we'll evaluate the Post portion in a subquery, and our outer query will select from the User table. Like the previous two queries, this query also ended up having a bad run-time:
PostAlias = Post.alias()
# Similar to previous, we are using join predicates and counting to
# determine the number of newer posts for a given post.
subquery = (Post
.select(Post.id, Post.content, Post.user)
.join(PostAlias, on=(
(PostAlias.user == Post.user) &
(PostAlias.timestamp >= Post.timestamp)))
.group_by(Post.id, Post.content, Post.user)
.having(fn.COUNT(Post.id) <= 3)
.alias('sq'))
query = (User
.select(User, subquery.c.content)
.join(subquery, on=(User.id == subquery.c.user_id))
.order_by(User.username, subquery.c.content))
I'll omit the corresponding SQL for brevity and because the query did not really show much improvement over the previous examples.
Trying LIMIT instead of COUNT
After giving up on trying to use COUNT(), I decided to try a different approach using subqueries and LIMIT. With this query, we'll create a subquery for each user which retrieves that user's posts ordered newest-to-oldest. A LIMIT 3 is applied to the subquery to ensure that a maximum of three posts are returned for each user. Then, in our outer query, we'll restrict the result set to those posts that correspond to a row in the correlated subquery.
PostAlias = Post.alias()
# The subquery here will calculate, for the user who created the
# post in the outer loop, the three newest posts. The expression
# will evaluate to `True` if the outer-loop post is in the set of
# posts represented by the inner query.
query = (Post
.select(Post, User)
.join(User)
.where(Post.id << (
PostAlias
.select(PostAlias.id)
.where(PostAlias.user == Post.user)
.order_by(PostAlias.timestamp.desc())
.limit(3))))
I think the corresponding SQL is a bit easier to read:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
WHERE t1.id IN (
SELECT t3.id
FROM post AS t3
WHERE (t3.user_id = t1.user_id)
ORDER BY t3.timestamp DESC
LIMIT 3
)
As with our previous attempts using COUNT(), these queries performed badly on both SQLite and Postgresql.
Window functions to the rescue
The final queries we will look at use window functions to calculate aggregates over windows of rows. For our use-case, these windows will be the set of posts created by a given user. We will be calculating the ordered rank of these posts and filtering so that we only retrieve the three newest posts by user.
The good news is that these queries were by far the most performant! The downside is that at the time of writing, SQLite does not support window functions, so they only work if you're using Postgresql.
Window functions are great, but there are some restrictions on how and where you can use them to filter result-sets, due to the order in which they're evaluated. To get them working I had to use some small workarounds.
The first example works by calculating the ranking of posts per user as a separate table, then uses join predicates to join the ranked posts to the canonical list of posts and users. Here is how it is expressed with Peewee:
PostAlias = Post.alias()
# Calculate the ranked posts per user as a separate "table".
subquery = (PostAlias
.select(
PostAlias.id,
fn.RANK().over(
partition_by=[PostAlias.user],
order_by=[PostAlias.timestamp.desc()]).alias('rnk'))
.alias('subq'))
# Join the ranked posts on the set of all posts, ensuring that we
# only get posts that are ranked less-than or equal-to *N*.
query = (Post
.select(
Post,
User)
.join(User)
.switch(Post)
.join(subquery, on=(
(subquery.c.id == Post.id) &
(subquery.c.rnk <= 3))))
This query corresponds to the following SQL query:
SELECT t1.id, t1.user_id, t1.content, t1.timestamp, t2.id, t2.username
FROM post AS t1
INNER JOIN user AS t2 ON (t1.user_id = t2.id)
INNER JOIN (
SELECT
t4.id,
RANK() OVER (
PARTITION BY t4.user_id
ORDER BY t4.timestamp DESC
) AS rnk
FROM post AS t4
) AS subq ON (
(subq.id = t1.id) AND
(subq.rnk <= 3))
Another way we can express the same query is by wrapping the ranked set of posts in an outer query and performing the filtering in the outer query. Here is how to do this with peewee:
PostAlias = Post.alias()
# The subquery will select the relevant data from the Post and
# User table, as well as ranking the posts by user from newest
# to oldest.
subquery = (PostAlias
.select(
PostAlias.content,
User.username,
fn.RANK().over(
partition_by=[PostAlias.user],
order_by=[PostAlias.timestamp.desc()]).alias('rnk'))
.join(User, on=(PostAlias.user == User.id))
.alias('subq'))
# Since we can't filter on the rank, we are wrapping it in a query
# and performing the filtering in the outer query.
query = (Post
.select(subquery.c.content, subquery.c.username)
.from_(subquery)
.where(subquery.c.rnk <= 3))
Almost all the logic for selecting and joining occurs in the subquery. The outer query is only responsible for filtering the ranked results.
Here is the resulting SQL:
SELECT subq.content, subq.username
FROM (
SELECT
t2.content,
t3.username,
RANK() OVER (
PARTITION BY t2.user_id
ORDER BY t2.timestamp DESC
) AS rnk
FROM post AS t2
INNER JOIN user AS t3 ON (t2.user_id = t3.id)
) AS subq
WHERE (subq.rnk <= 3)
Both of these window queries had similar run-times, but the second query (the wrapped subquery) was faster overall.
Lateral Joins
If you're using Postgresql 9.3 or newer, there's a cool feature called lateral joins that seems to have been designed exactly for this type of query. Lateral joins act like for each loops, where each joined query can be correlated with data from previously-joined queries. I stumbled on these late into writing the post so they aren't included in the performance section below, but I believe they are a great option if you're using Postgresql.
Here is how you would express the top posts query using lateral joins:
# We'll reference `Post` twice, so keep an alias handy.
PostAlias = Post.alias()
# Just like our O(n) example, the outer loop will be iterating
# over the users whose posts we are trying to find.
user_query = User.select(User.id, User.username).alias('uq')
# The inner loop will select posts and is correlated to the
# outer loop via the WHERE clause. Note that we are using a
# LIMIT clause!
post_query = (PostAlias
.select(PostAlias.content, PostAlias.timestamp)
.where(PostAlias.user == user_query.c.id)
.order_by(PostAlias.timestamp.desc())
.limit(3)
.alias('pq'))
# Now we join the outer and inner queries using the LEFT LATERAL
# JOIN. The join predicate is *ON TRUE*, since we're effectively
# joining in the post subquery's WHERE clause.
join_clause = Clause(
user_query,
SQL('LEFT JOIN LATERAL'),
post_query,
SQL('ON %s', True))
# Finally, we'll wrap these up and SELECT from the result.
query = (Post
.select(SQL('*'))
.from_(join_clause))
The corresponding SQL looks like this:
SELECT * FROM
(SELECT t2.id, t2.username FROM user AS t2) AS uq
LEFT JOIN LATERAL
(SELECT t2.content, t2.timestamp
FROM post AS t2
WHERE (t2.user_id = uq.id)
ORDER BY t2.timestamp DESC LIMIT 3)
AS pq ON true
It's definitely a bit unusual, but in my brief testing it seemed quite performant and looks like a viable solution to this type of problem. For more information, here are the Postgresql 9.3 release notes.
Measuring performance
As always, these results are not indicative of some absolute truth and you should always profile your code before and after attempting any optimizations. Your results may differ quite a bit from the results presented below, as they will be very dependent on the size and shape of your data, and the configuration and choice of database engine.
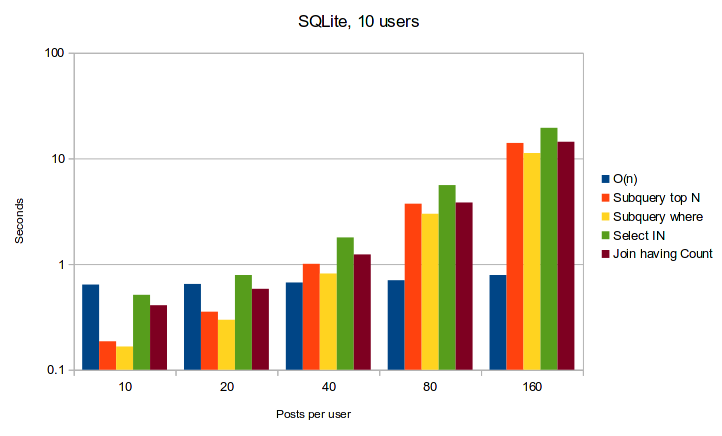
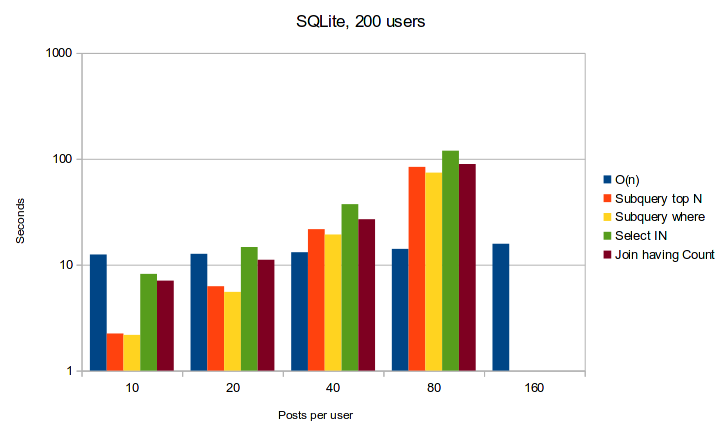
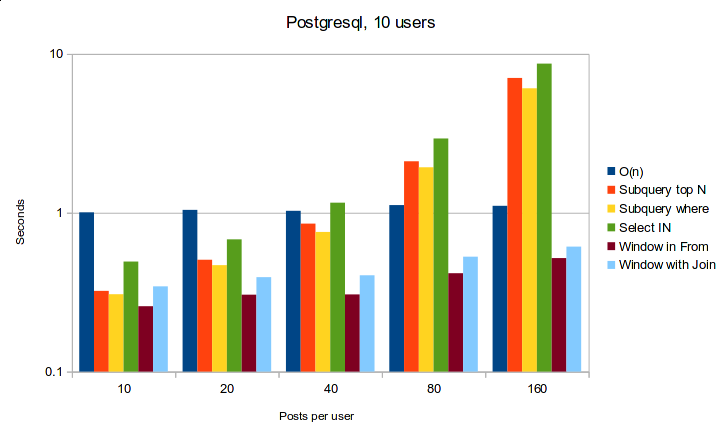
That being said, the results from my testing were pretty clear. If you're using Postgresql, window functions are going to be a lot faster and more scalable than the alternatives presented in this post. If you're using SQLite, then the results are a bit disconcerting as the most reliable performance can be achieved using the naive O(n) queries approach. The caveat with SQLite is that I was using an in-memory SQLite database for the benchmarks, and an on-disk database may have very different performance.
Below are some graphs showing the run-times of these queries with different ratios of users to posts.
SQLite
Postgresql

Thanks for reading
Thanks for taking the time to read this post, I hope you found it helpful. Please feel free to make a comment if you have any questions, comments, or suggestions. I'd really like to hear about other approaches for solving this type of problem with SQL, so please don't be shy!
Links
- Techniques for querying the top related item by group
- A tour of tagging schemas: many-to-many, bitmaps and more
- Querying tree structures using SQLite and the transitive closure extension
- Peewee documentation
- Window functions with Postgresql
- Excellent guide to using window functions
- Yet another window function tutorial
Comments (1)
Commenting has been closed.
r_kive | mar 03 2015, at 05:14pm
I'm most familiar with T-SQL rather than SQLite or PostreSQL, but in the past I've had a lot of success using APPLY to return the top N objects per group over using windowing fuctions. It doesn't look like SQLite supports it, but I believe the analog in PostreSQL is a lateral join. I'd be curious to see what kind of performance you see from that. I'd try something like this in T-SQL: