Redis and the Cost of Ambition

And they said, Go to, let us build us a city and a tower, whose top may reach unto heaven; and let us make us a name, lest we be scattered abroad upon the face of the whole earth.
I recently skimmed antirez's patch for adding an array type to Redis. The patch itself is not particularly noteworthy except as an example of how AI-assisted tooling can augment the abilities of a talented and tasteful systems engineer. What got me thinking was antirez' prose in the top of the pull-request, explaining the rationale for an array type:
Hashes give you random lookups, but you have to store an index as a key, and have no range visibility. Lists give you appending and trimming, but what is in the middle remains hard to access. Streams give you append-only events, which is another (useful, indeed) beast.
He could have also mentioned Redis' other array-ish faculties like JSON which has arrays natively, time-series, and sorted-sets, which can be made to behave like an array in some situations. Here we are in 2026, Redis is in a bit of a crisis, and yet is sitting with a massive PR to add a new array type. What is going on?
Let us make us a name
Redis has been through a lot over the last decade, driven partly by enterprise DBaaS dynamics, partly by second-system effects:
- Licensing: Redis Inc waged a scorched-earth campaign against its users by dropping BSD in 2024. When this blew up in its face, a strategic retreat was called and a parley offered: tri-licensing choose your own adventure with AGPLv3 as the lone OSI option (AGPL allows Redis Inc to claim being open source, but it's very different than BSD). The VC-backed company behind Redis is an interesting story in itself. Originally named Garantia Data, they were basically another NoSQL cloud hosting service. They got into Redis hosting, started calling themselves Redis Something-or-other, and eventually signed antirez to legitimize themselves. After a couple years they took over the trademark rights, which set the stage for the rugpull later. This post and the comment replies aged about as well as you might expect.
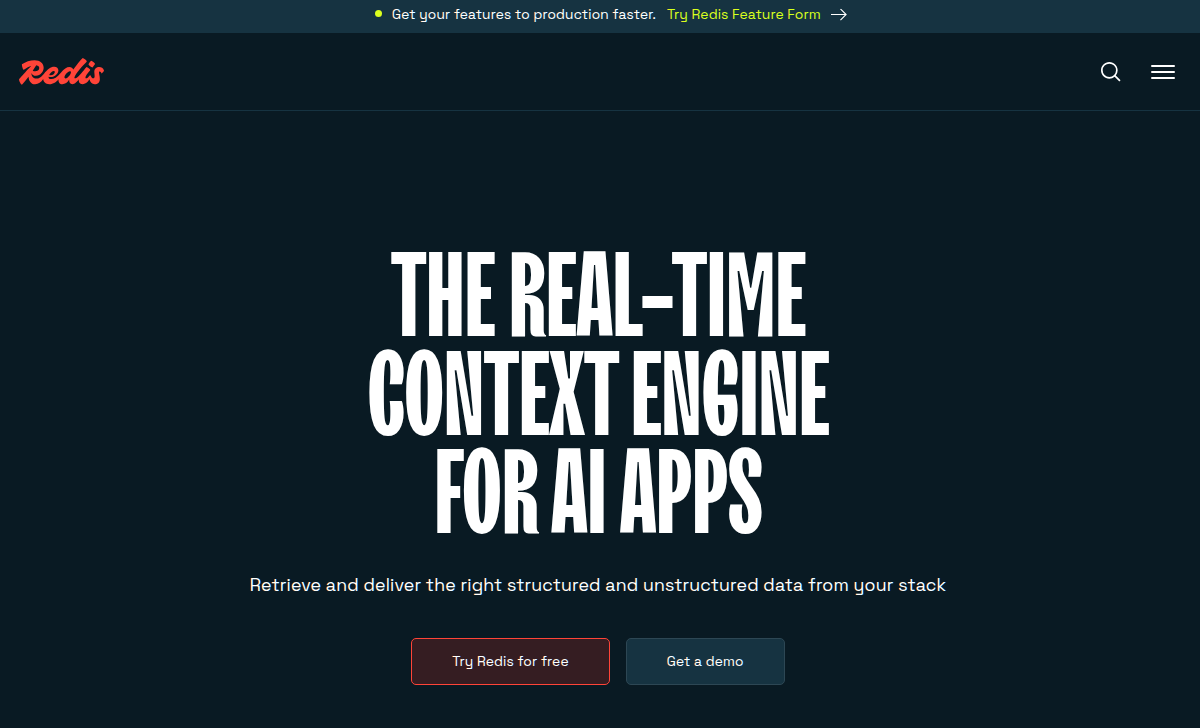
- Bloat and lock-in: Redis began with a handful of useful data-types. Over time the feature-set has grown (and grown) to include exotic data-structures, complex stateful systems (streams), semi-proprietary-ish modules (depending on what version you run). I was amazed when I pulled up Redis' landing page today and read that their positioning in 2026 is The Real-Time Context Engine for AI Apps. Additionally notable are the "Try Redis for Free" and "Get a Demo" buttons in this screenshot. I'm not sure which is more surprising - "for Free" or the enterprise sales-coded "demo" CTA.
- The "How many times do we have to tell you we are a web-scale database" dynamic. This is exemplified by the story around Sentinel, Cluster, Redis-Raft, and enterprise features like active-active geo-distribution®, Redis Flex®, Redis-on-Flash®, and whatever else.
- Protocol: RESP3 has a lot of sharp edges and breaks the fundamental assumption in RESP2 of request/reply. The new protocol is in my opinion a classic second system failure mode straight out of Brooks.
- First-class client-side caching support. In a kind of reductio-ad-absurdum, Redis (lately the cache), now needs a new protocol to support caching on the client side as well.
{kind=link}
What happened to dear old Redis, I wondered. And the more I thought about it, a satisfying explanation started to coalesce which explains all the above phenomena. To me, the picture that emerges is that of a solution that lost its identity through ambition.

The noble Brutus
Hath told you Caesar was ambitious.
If it were so, it was a grievous fault,
And grievously hath Caesar answered it.
Vernal delight and joy
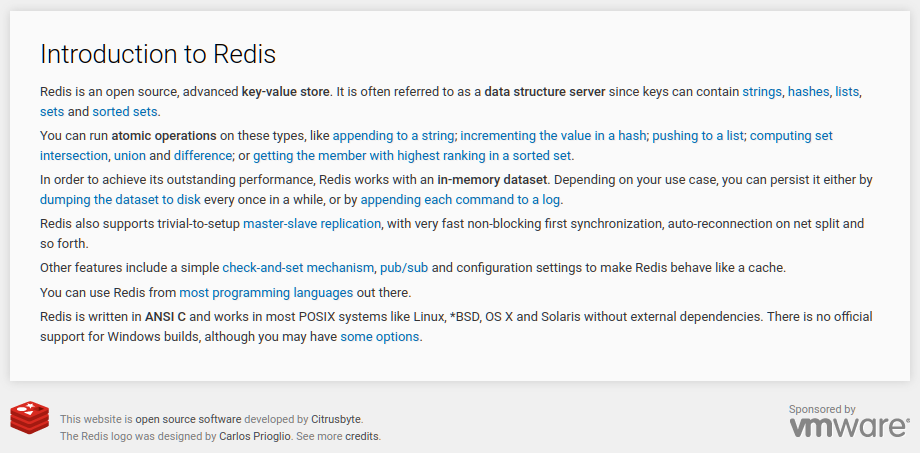
I would put it some time around 2011...that time of excitement when so many new ideas were coming in vogue among web and web-adjacent developer circles. When NoSQL was blasting off into its hype cycle, web scale was not used ironically yet, and the Bigtable and Dynamo papers were still widely read and discussed. Alongside this were Ruby on Rails, elegance (a desirable property for CRUD apps), web 2.0, REST and JSON. Redis perfectly captured the zeitgeist, and found its way into everyone's stack practically overnight. A capture from late 2011 has Redis describing itself as an advanced key-value store and data structure server. Notably absent is the word database.
Prior to Redis, memcached was that one indispensable piece of infrastructure running quietly on most web servers. In every deployment I've ever seen Memcached typically handles a variety of ad-hoc usages in addition to just caching, like locks, counters, rate-limits, stuff like that. So when Redis landed, the story at that time was something like "memcached but way better". Redis' name, Remote Dictionary Server, emphasized that it was a fast in-memory dictionary that could be used by all your services. In addition to blobs of bytes, Redis operated on a handful of tastefully-chosen data-structures (linked-list, hash-table, set, sorted-set), which vastly expanded the kinds of ad-hoc use-cases such a service could provide.
I want to call attention to some of the specific design considerations that I think Redis nailed perfectly, and which were instrumental in its initial success:
- Protocol: The beauty of Redis' wire protocol is that it is simple enough that it can be understood and coded in an hour, while being expressive enough that it can represent a number of rich data-types. Building a client library is simple and clean, and the protocol felt right. Anecdotally, my most popular blog post is a write your own Redis tutorial written nearly 10 years ago, which walks through building the protocol and a simple server.
- Single-threaded, event-driven, in-memory: by being single-threaded, all operations are guaranteed atomic, which eliminates a huge class of complexity and makes Redis easy to reason about. In order to make single-threaded work, the server needed to be implemented using non-blocking I/O. Operations on the data itself needed to be fast as hell. Put it together and you have a fast key/value store that can handle tons of clients and do it all from a single thread.
- Data structures: the primitives were chosen well and were suited to a web application's most common needs. Cache? Just use strings and an expiry. Queue? Use a list. Structured data? Use a hash. Locks, counters, rate-limiting, liveness, monitoring, leaderboards, whatever - all easy with the builtin data types.
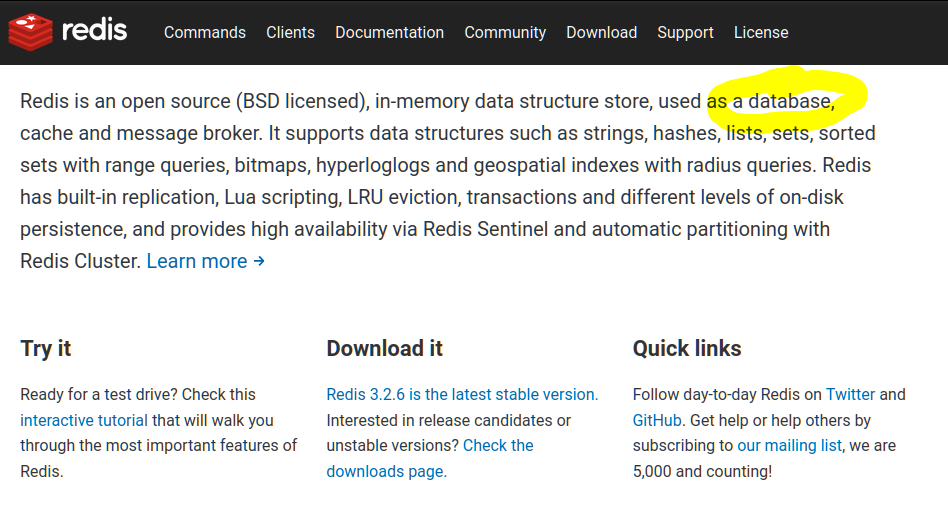
Adoption grew incredibly quickly and the project was, deservingly, a huge success. At some point along the way, the ambitions of the project changed. Redis took up the mantle of being a database:
Ambition
Some features have been genuinely useful additions, such as BZPOPMIN added in 5.0,
which allows a blocking-pop to be performed on a sorted-set (very nice when
using sorted-sets as a priority queue). Others struck me as being extremely
un-Redis-y, like ACLs. But mostly, there seems to be a desire to make Redis be
everything for everyone. The addition of these features closely tracks the
"latest cool thing" developers are talking about on HN over the last decade:
- MongoDB stores JSON, Redis should be a document database
- ElasticSearch does full-text search, Redis should be a search engine
- Graph databases are cool, Redis should be a graph database... (actually, maybe not).
- Kafka is generating a lot of buzz, let's be an event streaming platform
- ZooKeeper and other strongly-consistent databases are important. Let's ship it. (Aphyr's takedown).
- InfluxDB is cool. Let's be a time series database
- And if we don't have an AI story we'll be on the wrong side of history. Sales wants this done yesterday.
The problems with this mindset are two-fold. First, it ignores the factors that made Redis an indispensable part of everyone's stack in the first place. Redis was simple, the commands were orthogonal and tightly scoped, the protocol was clean, and it was conceptually coherent. Second, it ignores the fact that anyone who is serious about integrating full-text search / event stream processing / strong-consistency kv / time-series / vector storage is going to want the real thing, not some half-baked Redis module that inherits all of Redis' restrictions. Because, at the end of the day, the HA story on Redis is complicated. The persistence story is nuanced and there are important tradeoffs. The protocol pain and client fragmentation is a real hurdle. Redis does not aim to replace Postgres in your stack, and I would argue that ElasticSearch / RabbitMQ / etc / etc are similarly foundational pillars of any system.
Here is a quote from Aphyr's analysis of the initial development build of Redis-Raft:
...we found twenty-one issues, including long-lasting unavailability in healthy clusters, eight crashes, three cases of stale reads, one case of aborted reads, five bugs resulting in the loss of committed updates, one infinite loop, and two cases where logically corrupt responses could be sent to clients. The first version we tested (1b3fbf6) was essentially unusable...
Redis the cache and data-structure server is a fundamentally different proposition from "Redis the etcd" or any of the other databases named above. This is the disconnect.
He heard the sound of the trumpet, and took not warning
When antirez announced Disque back in 2015, I wrote a short piece explaining why I won't use it. My reasoning hinged on this comment by antirez:
Disque was designed a bit in astronaut mode, not triggered by an actual use case of mine, but more in response to what I was seeing people doing with Redis as a message queue and with other message queues.
I read that admission as being predictive of one outcome: abandonment. Projects developed in "astronaut mode", as personal challenges, as learning exercises are wonderful. Without a solid use-case, though, will the maintainer retain interest and focus in order to solve the long-tail of hard problems that crop up as soon as people start using it? While also maintaining Redis? HA message delivery is legitimately difficult to solve well, and whatever side of the CAP theorem you optimize for, you will be forced to make tradeoffs and solve some difficult problems.
Furthermore, I believed nobody would adopt. There were many mature message brokers in 2015. People used Redis as a message broker because they were already using Redis and it was good enough and simple. The need wasn't for a new message broker, nor was the need for Redis to become a more complex message broker. The project misread why people use Redis as a broker in the first place. People use Redis as a message broker specifically because they don't want to use something else.
I believe my predictions held true - Disque became abandonware almost as soon as it was announced, despite sitting at 8K stars on GitHub. Some time later it was rewritten as a Redis module, but that project is also sitting abandoned for the last 7 or 8 years.
I want to be clear that none of this discussion should be taken as overt or implied criticism of antirez. I have enormous respect for his talent and his taste. The main force I see at work in the development of Redis is, as I mentioned in the beginning, ambition. The ambition of a developer to solve complex problems, the ambition to be everything to everyone, the ambition of Redis' landlords to find a way to extract maximum revenue before AWS and GCP finish them off for good. There is nothing inherently wrong with ambition. The problem is when the ambition leads you to lose sight of what made you successful in the first place.
Valkey's existence and adoption is the wider market's final verdict on this dynamic. Rather than chase features and bullet points, Valkey has invested in the un-glamorous work of improving multi-threaded performance, memory efficiency, cluster reliability and throughput. Valkey's performance benchmarks are impressive and aimed squarely at the 80% of Redis users who just want the same features Redis shipped with back in 2011. There's no need for a new array type in Valkey's world.
Comments (2)
anonymous | may 12 2026, at 03:01pm
great article, I enjoy the way you write.
Commenting has been closed.
Daniel Rios | may 19 2026, at 08:17pm
good memories. Well written thanks.