Naive Bayes Classifier using Python and Kyoto Cabinet
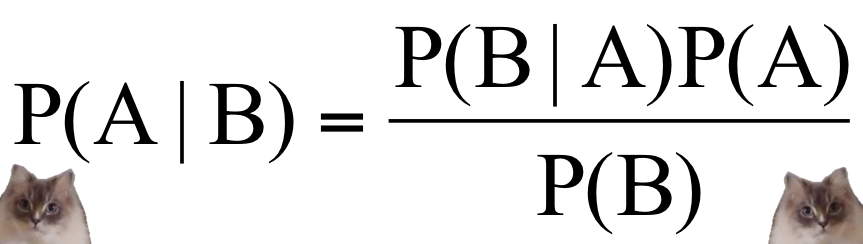
In this post I will describe how to build a simple naive bayes classifier with Python and the Kyoto Cabinet key/value database. I'll begin with a short description of how a probabilistic classifier works, then we will implement a simple classifier and put it to use by writing a spam detector. The training and test data will come from the Enron spam/ham corpora, which contains several thousand emails that have been pre-categorized as spam or ham.
The classifier structure will be based in part on the classifier presented in Toby Segaran's excellent book Programming Collective Intelligence. I recommend picking up a copy of this book! It is packed with useful information and practical examples of machine learning algorithms.
Overview of Probabilistic Classification
Our classifier will measure how often certain features correspond with one or more categories. Our goal is to be able to take a set of uncategorized features and, based on the observed likelihood that a given feature belongs to a category, predict an overall best category for the feature-set.
Because the classifier relies on historical observations, we need a way to train it. So how will we train the classifier? Or, to put it another way, what clues do we have that a message is spam? The answer is actually pretty simple: we will just use the individual words that make up the email message. These words and their association with either spam or ham messages will form the basis of our classifier.
Once we have associated the various features (words) with our two categories (spam and ham), we can calculate the probability that a given feature belongs to one category or another. For instance, the probability that the word money appears in a spam message is much higher than the probability it appears in a legitimate email. So how do you calculate this probability?
The calculation is actually pretty straightforward. Say we have trained our classifier using 200 email messages, 80 are spam and 120 are ham. Now, suppose that the word money appears in 25 spam emails, and only 5 of the ham emails. If we assume that an email is equally likely to be spam or ham, the probability that the word money indicates a spam document is calculated:
"money" is spam = P(spam has "money") / (P(spam has "money") + P(ham has "money"))
= (25 / 80) / ((25 / 80) + (5 / 120))
= .88, or 88%
The classifier will evaluate the probabilities for all the words in a document to come up with an overall probability of the likelihood a document is either spam or ham.
If you are interested in reading more about our classifier, perhaps the best introduction to Bayes' theorem is the Wikipedia introductory example – which is worth checking it out. For a more thorough introduction I recommend reading the excellent post An intuitive and short explanation of Bayes' Theorem.
- Wikipedia introduction to Bayes' Theorem
- Mathematical basis for probabilistic spam filter
- An intuitive and short explanation of Bayes' Theorem
What data do we need?
In order to calculate these probabilities, we are going to be storing counts of things, because it is these counts that allow us to calculate percentages, which can be combined to give an overall probability.
Recollecting the example above, we have:
let P(M|S) = probability that "money" appears in spam email (25 / 80)
let P(M|H) = probability that "money" appears in ham email (5 / 120)
P(S|M) is the probability that a message is spam, if it contains "money".
P(S|M) = P(M|S) / P(M|S) + P(M|H)
= (25 / 80) / ((25 / 80) + (5 / 120))
So we will need to store the following counts of things:
- How many documents are in each category.
- How often a word is associated with each category.
We'll use Kyoto Cabinet, a super fast key/value store, to persist our trained features and categories. Kyoto Cabinet has a couple different database types, but since we are going to be iterating over ranges of keys, we will use the B-Tree.
Installing Kyoto Cabinet

Before we can actually get started, we'll need to install Kyoto Cabinet and the Python bindings. At the time of writing, Kyoto Cabinet is at version 1.2.76 and the Python package is 1.18.
First we'll compile and install Kyoto Cabinet:
$ export KCVER="1.2.76"
$ wget http://fallabs.com/kyotocabinet/pkg/kyotocabinet-$KCVER.tar.gz
$ tar xzf kyotocabinet-$KCVER.tar.gz
$ cd kyotocabinet-$KCVER
$ ./configure
$ make
$ sudo make install
Now we'll install the python package. You can do this in a virtualenv if you want, or install system-wide.
$ export PYKCVER="1.18"
$ wget http://fallabs.com/kyotocabinet/pythonlegacypkg/kyotocabinet-python-legacy-$PYKCVER.tar.gz
$ tar xzf kyotocabinet-python-legacy-$PYKCVER.tar.gz
$ cd kyotocabinet-python-legacy-$PYKCVER
$ python setup.py build
$ python setup.py install # Note: you may need to use "sudo".
You can test your installation by running:
$ python -c 'import kyotocabinet; print kyotocabinet.VERSION'
1.2.76
Coding up the persistence layer
We'll begin by extending the kyotocabinet.DB class to add methods for storing and retrieving counts for the data described above.
We will have three types of keys:
- How many times a category is observed, e.g.
category.spamandcategory.ham. - How often a feature is associated with a given category, e.g.
feature2category.money.spam. - The total number of documents,
total-categories.
The following class provides convenience methods for incrementing and retrieving counts of features and categories.
import operator
import struct
import kyotocabinet as kc
class ClassifierDB(kc.DB):
"""
Wrapper for `kyotocabinet.DB` that provides utilities for working with
features and categories.
"""
def __init__(self, *args, **kwargs):
super(ClassifierDB, self).__init__(*args, **kwargs)
self._category_tmpl = 'category.%s'
self._feature_to_category_tmpl = 'feature2category.%s.%s'
self._total_count = 'total-count'
def get_int(self, key):
# Kyoto serializes ints big-endian 8-bytes long, so we need to unpack
# them using the `struct` module.
value = self.get(key)
if value:
return struct.unpack('>Q', value)[0]
return 0
def incr_feature_category(self, feature, category):
"""Increment the count for the feature in the given category."""
return self.increment(
self._feature_to_category_tmpl % (feature, category),
1)
def incr_category(self, category):
"""
Increment the count for the given category, increasing the total
count as well.
"""
self.increment(self._total_count, 1)
return self.increment(self._category_tmpl % category, 1)
def category_count(self, category):
"""Return the number of documents in the given category."""
return self.get_int(self._category_tmpl % category)
def total_count(self):
"""Return the total number of documents overall."""
return self.get_int(self._total_count)
def get_feature_category_count(self, feature, category):
"""Get the count of the feature in the given category."""
return self.get_int(
self._feature_to_category_tmpl % (feature, category))
def get_feature_counts(self, feature):
"""Get the total count for the feature across all categories."""
prefix = self._feature_to_category_tmpl % (feature, '')
total = 0
for key in self.match_prefix(prefix):
total += self.get_int(key)
return total
def iter_categories(self):
"""
Return an iterable that successively yields all the categories
that have been observed.
"""
category_prefix = self._category_tmpl % ''
prefix_len = len(category_prefix)
for category_key in self.match_prefix(category_prefix):
yield category_key[prefix_len:]
Now that we have a way of storing data, let's see how to train and classify documents. Also, just a note, but since we've encapsulated the logic for storing this data in its own class, it should be pretty easy to swap out different storage engines.
Building the classifier
The classifier exists to answer the following question:
Given a set of features, what is the probability they belong to a given category?
Because this is a supervised algorithm, we will need to train the classifier by populating it with counts for features and categories from a set of pre-categorized documents. Once trained, we will plug in a list of features and receive a list of possible categories and probabilities.
Let's define the skeleton of our classifier object, with code for connecting to the persistence layer:
class NBC(object):
"""
Simple naive bayes classifier.
"""
def __init__(self, filename, read_only=False):
"""
Initialize the classifier by pointing it at a database file. If you
intend to only use the classifier for classifying documents, specify
`read_only=True`.
"""
self.filename = filename
if not self.filename.endswith('.kct'):
raise RuntimeError('Database filename must have "kct" extension.')
self.db = ClassifierDB()
self.connect(read_only=read_only)
def connect(self, read_only=False):
"""
Open the database. Since Kyoto Cabinet only allows a single writer
at a time, the `connect()` method accepts a parameter allowing the
database to be opened in read-only mode (supporting multiple readers).
If you plan on training the classifier, specify `read_only=False`.
If you plan only on classifying documents, it is safe to specify
`read_only=True`.
"""
if read_only:
flags = kc.DB.OREADER
else:
flags = kc.DB.OWRITER
self.db.open(self.filename, flags | kc.DB.OCREATE)
def close(self):
"""Close the database."""
self.db.close()
def train(self, features, *categories):
"""
Train the classifier, storing the association of the given feature
set with the given categories.
"""
def feature_probability(self, feature, category):
"""
Calculate the probability that a particular feature is associated
with the given category.
"""
def weighted_probability(self, feature, category, weight=1.0):
"""
Determine the probability a feature corresponds to the given category.
The probability is weighted by the importance of the feature, which
is determined by looking at the feature across all categories in
which it appears.
"""
def document_probability(self, features, category):
"""
Calculate the probability that a set of features match the given
category.
"""
def weighted_document_probability(self, features, category):
"""
Calculate the probability that a set of features match the given
category, and weight that score by the importance of the category.
"""
def classify(self, features, limit=5):
"""
Classify the features by finding the categories that match the
features with the highest probability.
"""
Let's start with the training method. This method will simply iterate through the features and categories provided, incrementing counts in the database.
def train(self, features, *categories):
"""
Increment the counts for the features in the given categories.
"""
for category in categories:
for feature in features:
self.db.incr_feature_category(feature, category)
self.db.incr_category(category)
Believe it or not, the above is all the code we need to start training our classifier! Of course, we're not done yet — we need to write the code to classify new documents. Let's start plugging the training data into some methods we can use to classify documents.
def feature_probability(self, feature, category):
"""
Calculate the probability that a particular feature is associated
with the given category.
"""
fcc = self.db.get_feature_category_count(feature, category)
if fcc:
category_count = self.db.category_count(category)
return float(fcc) / category_count
return 0
def weighted_probability(self, feature, category, weight=1.0):
"""
Determine the probability a feature corresponds to the given category.
The probability is weighted by the importance of the feature, which
is determined by looking at the feature across all categories in
which it appears.
"""
# Calculate the "initial" probability that the given feature will
# appear in the category.
initial_prob = self.feature_probability(feature, category)
# Sum the counts of this feature across all categories -- e.g.,
# how many times overall does the word "money" appear?
totals = self.db.get_feature_counts(feature)
# Calculate the weighted average. This is slightly different than what
# we did in the above example, and will help give us a more evenly weighted
# result and prevents us returning 0.
return ((weight * 0.5) + (totals * initial_prob)) / (weight + totals)
The above weighted_probability function allows us to calculate the probability that a feature is associated with a given category. Now it will get more interesting as we will be calculating the probability that a set of features matches a category. To calculate this, we'll simply multiply together all the probabilities of the individual features:
def document_probability(self, features, category):
"""
Calculate the probability that a set of features match the given
category.
"""
feature_probabilities = [
self.weighted_probability(feature, category)
for feature in features]
return reduce(operator.mul, feature_probabilities, 1)
Like we did with the features in weighted_probability, we will also weight the document probabilities.
def weighted_document_probability(self, features, category):
"""
Calculate the probability that a set of features match the given
category, and weight that score by the importance of the category.
"""
if self.db.total_count() == 0:
# Avoid divison by zero.
return 0
# Calculate the probability that a document will have the given category.
# In our example this is (80 / 200) for spam, (Spam docs / Total docs).
cat_prob = (float(self.db.category_count(category)) /
self.db.total_count())
# Get the probabilities of each feature for the given category.
doc_prob = self.document_probability(features, category)
# Weight the document probability by the category probability.
return doc_prob * cat_prob
Finally we come to the heart of the classifier, the method that classifies a set of features. This will calculate the probability for each category (i.e., the probability for spam and ham) and then return the calculated probabilities sorted so the best match is first:
def classify(self, features, limit=5):
"""
Classify the features by finding the categories that match the
features with the highest probability.
"""
probabilities = {}
for category in self.db.iter_categories():
probabilities[category] = self.weighted_document_probability(
features,
category)
return sorted(
probabilities.items(),
key=operator.itemgetter(1),
reverse=True)[:limit]
That's all there is to it! In the next section we will use this classifier to process data from Enron's spam corpus.
Processing data from the Enron spam corpus

To follow along, you'll need to download the Enron spam corpora. The corpuses.tar.gz file contains 3 different collections of spam / ham emails from Enron and will be used to train and test the classifier.
Let's create a new script called enron.py that we'll use to read the emails from the Enron corpora and train our classifier. The first function we write will read all the files in a given corpus and train the classifier.
import os
# Import our classifier (whatever you named the file), assumed to be
# in same directory.
from classifier import NBC
def train(corpus='corpus'):
classifier = NBC(filename='enron.kct')
curdir = os.path.dirname(__file__)
# Paths to spam and ham documents.
spam_dir = os.path.join(curdir, corpus, 'spam')
ham_dir = os.path.join(curdir, corpus, 'ham')
# Train the classifier with the spam documents.
train_category(classifier, spam_dir, 'spam')
# Train the classifier with the ham documents.
train_category(classifier, ham_dir, 'ham')
return classifier
def train_category(classifier, path, category):
files = os.listdir(path)
print 'Preparing to train %s %s files' % (len(files), category)
for filename in files:
with open(os.path.join(path, filename)) as fh:
contents = fh.read()
# extract the words from the document
features = extract_features(contents)
# train the classifier to associate the features with the category
classifier.train(features, category)
As you can see in the above code, we are calling a function extract_features to extract the words from the file contents. Our spam detector will simply use the words from the email message as the features.
def extract_features(s, min_len=2, max_len=20):
"""
Extract all the words in the string `s` that have a length within
the specified bounds.
"""
words = []
for w in s.lower().split():
wlen = len(w)
if wlen > min_len and wlen < max_len:
words.append(w)
return words
After training the classifier, let's write a function to test it on a different corpus. The following function will classify all the spam and ham documents, recording whether the classifier guessed correctly or not.
def test(classifier, corpus='corpus2'):
curdir = os.path.dirname(__file__)
# Paths to spam and ham documents.
spam_dir = os.path.join(curdir, corpus, 'spam')
ham_dir = os.path.join(curdir, corpus, 'ham')
correct = total = 0
for path, category in ((spam_dir, 'spam'), (ham_dir, 'ham')):
filenames = os.listdir(path)
print 'Preparing to test %s %s files from %s.' % (
len(filenames),
category,
corpus)
for filename in os.listdir(path):
with open(os.path.join(path, filename)) as fh:
contents = fh.read()
# Extract the words from the document.
features = extract_features(contents)
results = classifier.classify(features)
if results[0][0] == category:
correct += 1
total += 1
pct = 100 * (float(correct) / total)
print '[%s]: %s documents, %02f%% accurate!' % (corpus, total, pct)
Let's make it so that when we run our script from the command line it will train itself using corpus and will then test itself against the other 2 corpora:
if __name__ == '__main__':
classifier = train()
test(classifier, 'corpus2')
test(classifier, 'corpus3')
classifier.close()
os.unlink('enron.kct')
Here is the output I get from running the script (took about 90s to run):
$ python enron.py
Preparing to train 1500 spam files
Trained 1500 files
Preparing to train 3672 ham files
Trained 3672 files
Preparing to test 3675 spam files from corpus2.
Preparing to test 1500 ham files from corpus2.
[corpus2]: processed 5175 documents, 90.318841% accurate
Preparing to test 4500 spam files from corpus3.
Preparing to test 1500 ham files from corpus3.
[corpus3]: processed 6000 documents, 85.533333% accurate
90% and 85%! Not too bad.
Improving Accuracy
While the accuracy is significantly better than a random guess, it could definitely be improved. How can we improve the accuracy of the classifier? Reflecting on how the classifier works, the absolute most important thing to do is to ensure we are extracting high quality features.
Here are a couple ideas for improving the features:
- Filter out noise while extracting words, things like common stop words.
- Treat the words in the email subject as distinct features. Perhaps the subject lines of spam messages have a lot in common?
- Treat bigrams as features. Maybe spam messages use distinctive two-word combinations that aren't often seen in regular messages.
- Check for things like words in all caps or the presence of links in the text and record these as boolean features.
- Since the features themselves are identified by a string, you can indicate a feature is a subject word by prefixing it with an s:. Or you can add meta-features like ALL_CAPS or CONTAINS_LINKS.
For instance, simply by filtering out stop words I was able to bump the accuracy up by 2%:
$ python enron2.py
[corpus2]: processed 5175 documents, 91.826087% accurate
[corpus3]: processed 6000 documents, 87.350000% accurate
Closing Remarks
I hope you enjoyed reading this post! As you may have noticed, the classifier module is not written in such a way that it is spam-specific, so you can adapt it to all sorts of other uses. One example might be suggesting tags for a blog post. If you’re interested in learning more, I again would suggest picking up a copy of Programming Collective Intelligence.
Additionally, the ClassifierDB wrapper class implements a fairly simple interface, so you could try implementing the persistence layer using Redis or SQLite.
All the source code can be found on GitHub: https://gist.github.com/coleifer/2d66b9671420ca2856a8
You can also clone the code using git:
$ git clone https://gist.github.com/coleifer/2d66b9671420ca2856a8 classifier
Thanks for taking the time to read this post!
How will we ever classify all these kitties?

Links
Here are some blog posts on related topics:
- Using Python and k-means to find the dominant colors in images
- Introduction to the fast, new UnQLite Python bindings
Comments (1)
Commenting has been closed.
IamUkranianPleseDontInvadeUs | feb 04 2015, at 11:31pm
Nice post again. Specially liked the cats in topic.