Blog Entries all / by tag / by year / popular

Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.
Optimistic locking in Peewee ORM

In this post I'll share a simple code snippet you can use to perform optimistic locking when updating model instances. I've intentionally avoided providing an implementation for this in peewee, because I don't believe it will be easy to find a one-size-fits-all approach to versioning and conflict resolution. I've updated the documentation to include the sample implementation provided here, however.
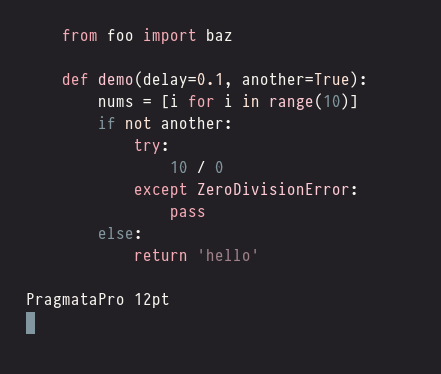
Monospace Font Favorites
For the past six months or so, I've been experimenting with a variety of monospace fonts in a quest to find the perfect coding font. While I haven't found a clear winner, I have found a dozen nice-looking fonts and learned a lot about typefaces in general. I've also learned quite a bit about font rendering on Linux, which I hope to summarize in a separate post soon.
In this post I'd like to share some screenshots (or "swatches") of my favorite fonts.
Suffering for fashion: a glimpse into my Linux theming toolchain

My desktop at the time of writing.
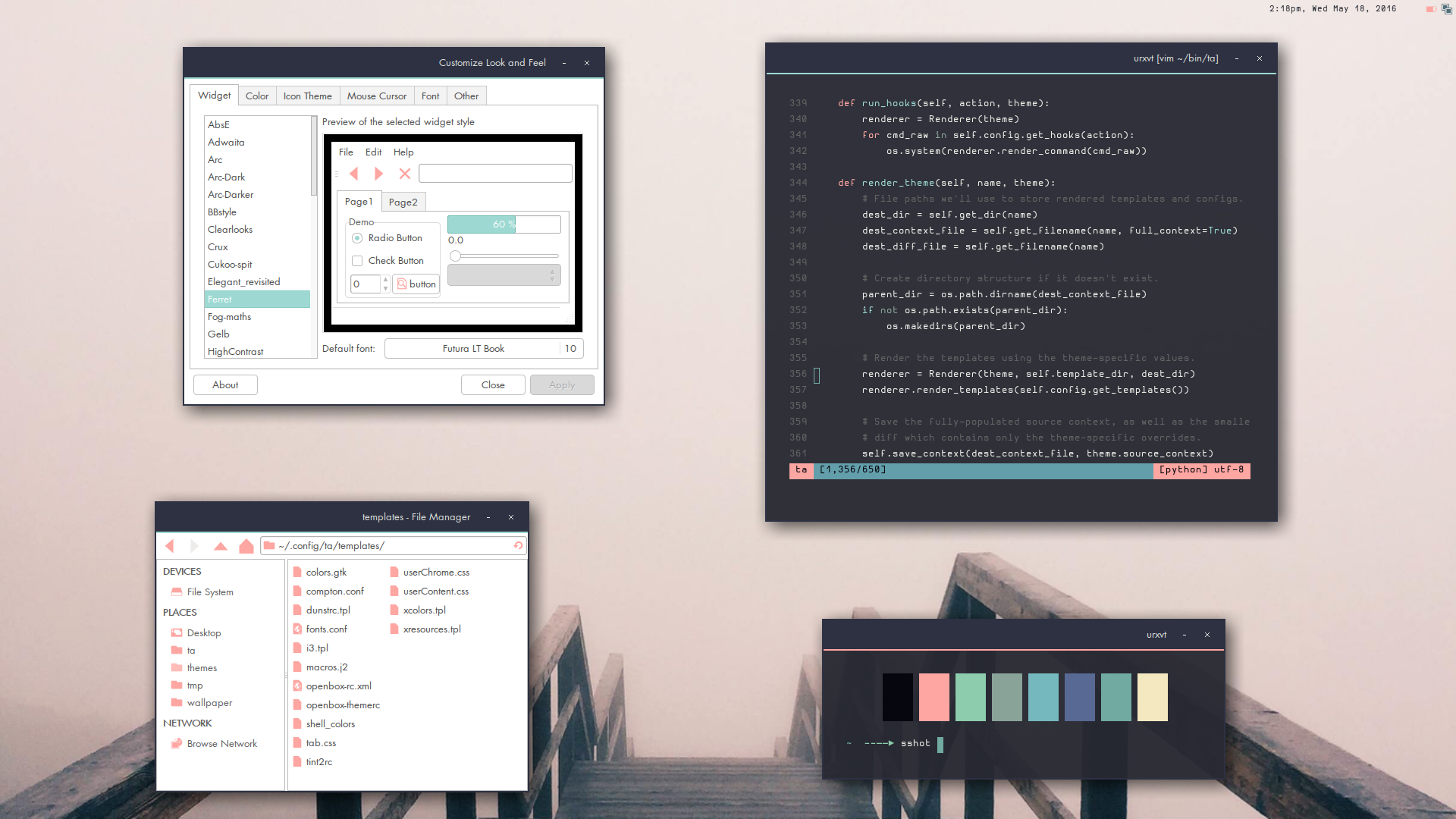
Here it is a couple months later.
It's been over 2 years since I wrote about the tooling I use to theme my desktop, so I thought I'd post about my current scripts...
"For Humans" makes me cringe

When Kenneth Reitz created the requests library, the Python community rushed to embrace the project, as it provided (finally) a clean, sane API for making HTTP requests. He subtitled his project "Python HTTP Requests for Humans", referring, I suppose, to the fact that his API provided developer-friendly APIs. If naming things "for humans" had stopped there, that would have been fine with me, but instead there's been a steady stream of new projects describing themselves as being "For Humans" and I have issues with that.
Measuring Nginx Cache Performance using Lua and Redis

Shortly after launching my Nginx-based cache + thumbnailing web-service, I realized I had no visibility into the performance of the service. I was curious what my hit-ratios were like, how much time was spent during a cache-miss, basic stuff like that. Nginx has monitoring tools, but it looks like they're only available to people who pay for Nginx Plus, so I decided to see if I could roll my own. In this post, I'll describe how I used Lua, cosockets, and Redis to extract real-time metrics from my thumbnail service.
Nginx: a caching, thumbnailing, reverse proxying image server?
![]()
A month or two ago, I decided to remove Varnish from my site and replace it with Nginx's built-in caching system. I was already using Nginx to proxy to my Python sites, so getting rid of Varnish meant one less thing to fiddle with. I spent a few days reading up on how to configure Nginx's cache and overhauling the various config files for my Python sites (so much for saving time). In the course of my reading I bookmarked a number of interesting Nginx modules to return to, among them the Image Filter module.
Five reasons you should use SQLite in 2016
![]()
If you haven't heard, SQLite is an amazing database capable of doing real work in real production environments. In this post, I'll outline 5 reasons why I think you should use SQLite in 2016.
Announcing sophy: fast Python bindings for Sophia Database
![]()
Sophia is a powerful key/value database with loads of features packed into a simple C API. In order to use this database in some upcoming projects I've got planned, I decided to write some Python bindings and the result is sophy. In this post, I'll describe the features of Sophia database, and then show example code using sophy, the Python wrapper.
Here is an overview of the features of the Sophia database:
- Append-only MVCC database
- ACID transactions
- Consistent cursors
- Compression
- Ordered key/value store
- Range searches
- Prefix searches