Entries from 2017 « 2016 / all / by tag / popular / 2018 »
Write your own miniature Redis with Python
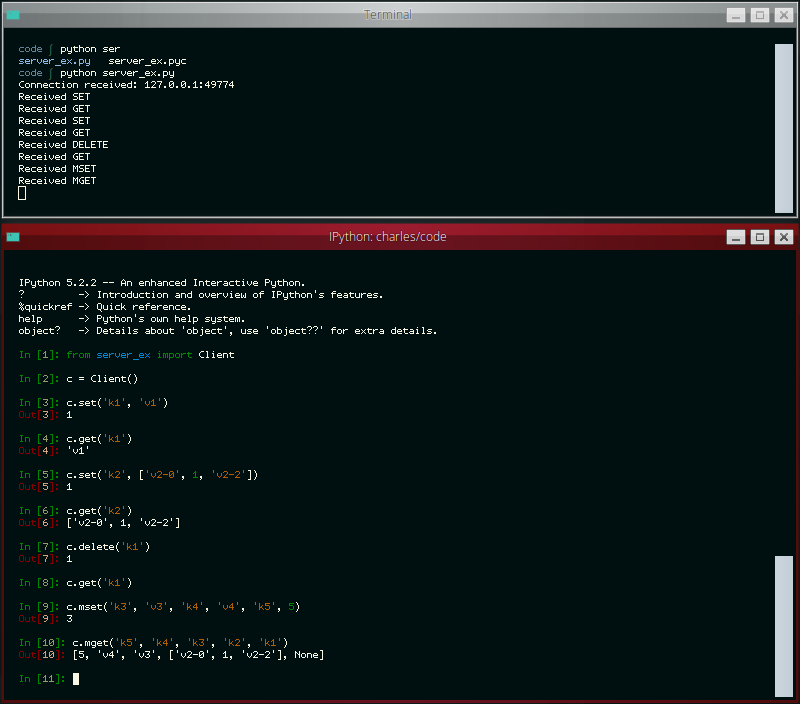
The other day the idea occurred to me that it would be neat to write a simple Redis-like database server. While I've had plenty of experience with WSGI applications, a database server presented a novel challenge and proved to be a nice practical way of learning how to work with sockets in Python. In this post I'll share what I learned along the way.
The goal of my project was to write a simple server that I could use with a task queue project of mine called huey. Huey uses Redis as the default storage engine for tracking enqueued jobs, results of finished jobs, and other things. For the purposes of this post, I've reduced the scope of the original project even further so as not to muddy the waters with code you could very easily write yourself, but if you're curious, you can check out the end result here (documentation).
The server we'll be building will be able to respond to the following commands:
- GET
<key> - SET
<key><value> - DELETE
<key> - FLUSH
- MGET
<key1>...<keyn> - MSET
<key1><value1>...<keyn><valuen>
We'll support the following data-types as well:
- Strings and Binary Data
- Numbers
- NULL
- Arrays (which may be nested)
- Dictionaries (which may be nested)
- Error messages
LSM Key/Value Storage in SQLite3
![]()
Several months ago I was delighted to see a new extension appear in the SQLite source tree. The lsm1 extension is based on the LSM key/value database developed as an experimental storage engine for the now-defunct SQLite4 project. Since development has stopped on SQLite4 for the forseeable future, I was happy to see this technology being folded into SQLite3 and was curious to see what the SQLite developers had in mind for this library.
The SQLite4 LSM captured my interest several years ago as it seemed like a viable alternative to some of the other embedded key/value databases floating around (LevelDB, BerkeleyDB, etc), and I went so far as to write a set of Python bindings for the library. As a storage engine, it seems to offer stable performance, with fast reads of key ranges and fast-ish writes, though random reads may be slower than the usual SQLite3 btree. Like SQLite3, the LSM database supports a single-writer/multiple-reader transactional concurrency model, as well as nested transaction support.
The LSM implementation in SQLite3 is essentially the same as that in SQLite4, plus some additional bugfixes and performance improvements. Crucially, the SQLite3 implementation comes with a standalone extension that exposes the storage engine as a virtual table. The rest of this post will deal with the virtual table, its implementation, and how to use it.
Ditching the Task Queue for Gevent
Task queues are frequently deployed alongside websites to do background processing outside the normal request/response cycle. In the past I've used them for things like sending emails, generating thumbnails, warming caches, or periodically fetching remote resources. By pushing that work out of the request/response cycle, you can increase the throughput (and responsiveness) of your web application.
Depending on your workload, though, it may be possible to move your task processing into the same process as your web server. In this post I'll describe how I did just that using gevent, though the technique would probably work well with a number of different WSGI servers.
Going Fast with SQLite and Python
![]()
In this post I'd like to share with you some techniques for effectively working with SQLite using Python. SQLite is a capable library, providing an in-process relational database for efficient storage of small-to-medium-sized data sets. It supports most of the common features of SQL with few exceptions. Best of all, most Python users do not need to install anything to get started working with SQLite, as the standard library in most distributions ships with the sqlite3 module.


Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.