SQLite: Small. Fast. Reliable. Choose any three.
![]()
SQLite is a fantastic database and in this post I'd like to explain why I think that, for many scenarios, SQLite is actually a great choice. I hope to also clear up some common misconceptions about SQLite.
Concurrency
As the maintainer of an ORM, I get asked a lot of questions about databases. One of the more common questions is:
Can I use SQLite in my web app? I've heard it doesn't do concurrency.
SQLite does support multiple concurrent connections, and therefore it can be used with a multi-threaded or multi-process application. The catch is that when SQLite opens a write transaction, it will lock all the tables.
Locking the entire database may sound scary, but typically writes occur very quickly, and there are ways to make them faster (discussed below). So, even though the database is locked while you are writing, the writes happen so quickly that it's only likely to be an issue if you are doing a lot of concurrent writes.
Additionally, the Python SQLite driver will automatically retry queries that fail due to the
database being locked. You can configure this behavior using the timeout
parameter, which has a default value of 5 seconds. Since most writes occur
in milliseconds, the 5 second timeout is a relative eternity.
If you'd like to learn more about SQLite's locking behavior, I'd suggest reading the SQLite locking documentation.
Faster concurrent operations
By using write-ahead logging (WAL), available since version 3.7.0, you can gain additional speed when performing concurrent operations. WAL allows multiple readers to operate on the database, even while a write is occuring. To enable WAL, execute the following query after opening a new connection to the database:
PRAGMA journal_mode=WAL;
Another way to achieve higher concurrency is to compile BerkeleyDB with a SQLite-compatible API. Then, by compiling the python SQLite driver against the BerkeleyDB SQLite library, you can achieve some pretty awesome performance. The image below shows how BerkeleyDB delivers many more transactions-per-second when using multiple threads.
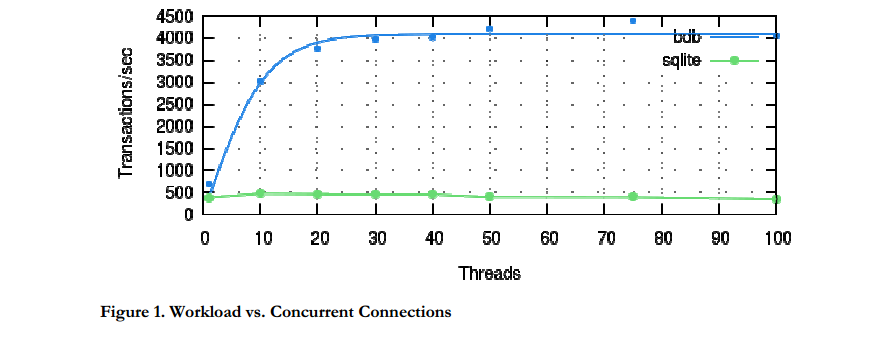
If you're interested in trying out the BerkeleyDB SQLite library, compile BerkeleyDB with SQLite compatibility enabled, then build the Python SQLite driver against the custom SQLite shared library.
SQLite is not a "real" database
I've occasionally heard people say that SQLite is not a real database. The reasons for this opinion vary, but here are some that come to mind:
- Column data-types are not enforced, e.g. you can store text in an integer column.
- After a table is created, columns cannot be dropped or renamed (though you can add new columns).
- Database is locked for writes.
On the other hand, look at all the features that SQLite does provide:
- Transactions are atomic, consistent, isolated and durable (ACID).
- Support for a wide variety of SQL queries.
- Indexes, constraints, foreign keys, views, and partial support for triggers.
- Savepoints (nested transactions).
- Multiple concurrent connections to the database.
- Databases can be up to 140TB in size.
- SQLite can recover from program crashes, operating system crashes, and even power failures.
- Write your own extensions, define your own aggregates, collations, and SQL functions.
- Full-text search and other neat extensions.
Every database I've used differs slightly in the subset of SQL it supports,
and even though the data-types and ALTER TABLE behavior of SQLite are unusual,
I don't think either of them means that SQLite is not a real database.
Working around ALTER TABLE
The standard approach when altering or dropping columns from a SQLite database is to create a new table, copy the data you want, then replace the old table with the new. This can be quite cumbersome, especially when your table has a large number of columns.
To make this easier, I wrote a lightweight schema migrations extension for the peewee ORM. I'm not positive, but I imagine something similar exists for SQLAlchemy users. This extension will automatically handle creating the temporary table and copying over the data, so all you need to do is tell peewee which columns to drop (or rename, etc):
from playhouse.migrate import *
migrator = SqliteMigrator('mydata.db')
migrate(
migrator.drop_column('some_table', 'some_column'),
migrator.drop_column('some_table', 'another_column'),
migrator.rename_column('some_table', 'old_colname', 'new_colname'),
)
Even if you aren't using an ORM you can still use the migrator library to help with schema changes.
When would SQLite not be a good choice?
Now that I've sung the praises of SQLite and described some ways to work around its limitations, I'd like to describe some scenarios where SQLite would be a bad choice.
- Multiple servers communicating with the database over the network, or situations in which you plan to run your database on a separate server.
- Highly concurrent applications, including websites that receive a very large amount of traffic.
- Very large data-sets.
The main consideration there, I think, is when you have multiple web-servers and need to connect to your database over the network. While you can use SQLite over an NFS mount, for instance, the SQLite documentation seems to indicate that this may be buggy.
Wrapping up
Both SQLite and Postgres have their place in the developer's toolkit. Postgres is a phenomenal database, and I could go on and on about how awesome it is. But this post is about clearing up some misconceptions about SQLite, and hopefully convincing you that it is a great choice for many applications, including web development.
Donald Knuth said,
Premature optimization is the root of all evil.
In that vein, don't be afraid to give SQLite a try -- I'd be willing to bet it would work very well for you!
Oh, and in case you were wondering, yes -- this site uses SQLite!
Edit
I was asked on a Reddit discussion to quantify how much traffic a site should receive before it is "too much". This obviously depends on a lot of factors (ratio of reads to writes, length of time it takes to perform a write, disk speed, etc). I will share a quote from the SQLite docs, though:
SQLite usually will work great as the database engine for low to medium traffic websites (which is to say, 99.9% of all websites). The amount of web traffic that SQLite can handle depends, of course, on how heavily the website uses its database. Generally speaking, any site that gets fewer than 100K hits/day should work fine with SQLite. The 100K hits/day figure is a conservative estimate, not a hard upper bound. SQLite has been demonstrated to work with 10 times that amount of traffic.
Links
Thanks for taking the time to read this post, if you have any questions or comments, please feel free to leave a comment below.
If you'd like to learn more about the topics mentioned in this post, here are some links which you might find useful:
- SQLite concurrency and locking and write-ahead logging.
- BerkeleyDB SQLite API and comparison of performance.
- Peewee schema migrations.
Comments (10)
Sean Beck | jul 17 2014, at 02:55pm
I'm glad others like SQLite as much as I do! It is lightweight yet can do heavy things
Rajaseelan | jul 15 2014, at 07:27pm
Hmmm.... you have a point on concurrency. I'll try that for my 'small' admin type apps and see where I go with this :)
Kareem | jul 15 2014, at 12:45pm
Thank you for your article, I was not aware sqlite had so many excellent features. I will certainly consider it for my future applications.
Charlie | jul 15 2014, at 11:48am
I wrote a little script to stress-test SQLite using python's multi-processing module. I was able to spin up over 200 processes, each writing 20 rows, without issue:
https://gist.github.com/coleifer/ec7535128b550b96beda
Dave | jul 15 2014, at 11:46am
Thanks, I'm using sqlite in a web project because it's my "default start-out choice" because it's so simple to set up for development, but it's good to know I can just keep rolling with it for most projects. I'm curious to see the numbers when I go into production.
Howard Chu | jul 15 2014, at 11:35am
SQLite3 using LMDB is even smaller, faster, and more reliable than either of the the above. Have a look... https://gitorious.org/mdb/sqlightning
GJR | jul 15 2014, at 07:22am
Hi. Thanks for posting the article. It would be great if you addressed the topic of high availability and resilience as well as this is typical the key point that an 'industrial' application needs to concern itself with.
Jimmy Chen | jul 14 2014, at 10:06pm
Thanks for covering this. I was debating whether to use SQLite for my XMPP server implementation.
Jack River | jul 14 2014, at 09:50pm
Great article! Learnt a lot of new stuff about SQLite, thank you.
Commenting has been closed.
Wayne Werner | jul 21 2014, at 03:38pm
Another awesome option is using SQLite as an application file format (see the amazing slides http://www.pgcon.org/2014/schedule/attachments/319_PGCon2014OpeningKeynote.pdf)