Saturday morning hack: personalized news digest with boolean query parser

Because I had so much fun writing my last Saturday morning hack, I thought I would share another little hack. I was thinking that I really enjoy my subscription to Python weekly and wouldn't it be great if I had a personal email digest containing just the types of things that interest me? I regularly cruise reddit and hacker hater news but in my opinion there's a pretty low signal-to-noise ratio. Occasionally I stumble on fascinating content and that's what keeps me coming back.
I wanted to write an app that would search the sites I read and automatically create an email digest based on search terms that I specified. I recently swapped my blog over to SQLite and I love that the SQLite full-text search extension lets you specify boolean queries. With that in mind, I decided that I would have a curated list of boolean search queries which would be used to filter content from the various sites I read. Any articles that match my search would then be emailed to me.
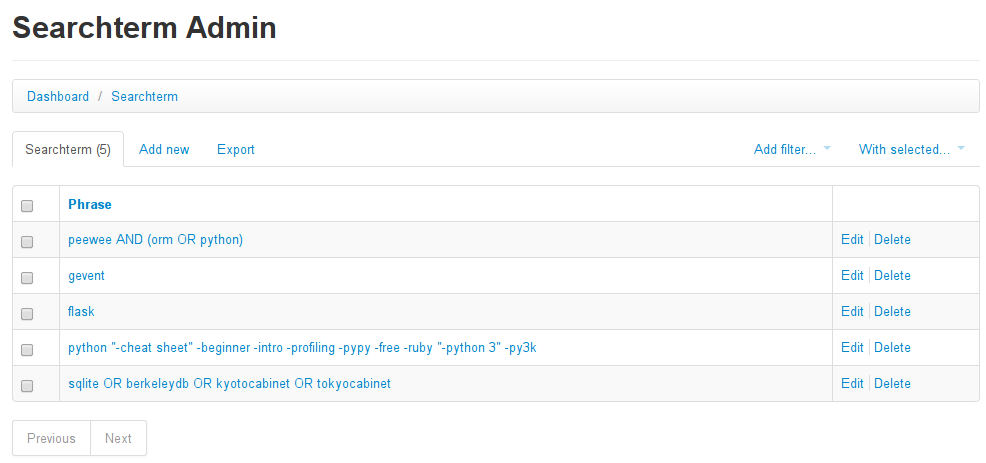
Here are some of my search terms, which I am viewing in the flask-peewee admin interface:
Implementation
Here is the bill of materials:
- Huey task queue, which will be used to periodically check for new articles and email them to me. If you want you could just write a cronjob, of course.
- Peewee ORM for storing the search terms and the links, so I don't send myself the same link twice.
The first thing I did was define my database models. As you see, they are very simple:
from peewee import *
class BaseModel(Model):
class Meta:
database = SqliteDatabase('search_terms.db')
class SearchTerm(BaseModel):
phrase = CharField()
def __unicode__(self):
return self.phrase
def parse(self):
# TODO: we will add this method in a bit.
pass
def test(self, title):
# TODO: we will add this method in a bit.
pass
class SavedLink(BaseModel):
title = CharField(max_length=255)
url = CharField(index=True)
timestamp = DateTimeField(default=datetime.datetime.now)
Parsing boolean expressions
Now we come to the interesting part: the boolean expression parser. If you looked closely at the screenshot included above, you can see a few SearchTerm objects I've specified. Here are the actual phrases:
peewee AND (orm OR python)geventflaskpython "-cheat sheet" -beginner -intro -pypy -free -"python 3"sqlite OR unqlite OR berkeleydb OR kyotocabinet OR tokyocabinet
Search terms consist of phrases joined by conjunctions (AND and OR). Search terms can be negated, indicated by prefixing the term with a dash (-) character. Search terms can also be nested, as in the first example, which will match articles containing the word peewee and also orm or python.
The first step is to split the search term into one or more tokens, which can be accomplished with a short regex. The regex splits on quoted text, parentheses and whitespace:
'(\".+?\"|\(|\s+|\))'
The parsing code maintains a stack of Node objects which comprise the query tree. The Node class is very basic, and there are two subclasses which are used to represent AND and OR nodes:
class Node(object):
def __init__(self, text=''):
self.text = text
self.children = []
def __repr__(self):
if not self.children:
return self.text
else:
return '%s(%s)' % (
self.text,
' '.join(str(node) for node in self.children))
class AndNode(Node):
pass
class OrNode(Node):
pass
Putting this together, here is the SearchTerm.parse method, which splits the phrase into tokens, then builds a tree of node objects.
def parse(self):
node_map = {'AND': AndNode, 'OR': OrNode}
# The default conjunction is AND, so if the phrase simply consists of
# one or more words, "and"- them together.
stack = [AndNode('AND')]
for token in re.split('(\".+?\"|\(|\s+|\))', self.phrase):
# Ignore any empty tokens.
token = token.strip()
if not token:
continue
if token == '(':
stack.append(Node())
elif token == ')':
node = stack.pop()
if len(stack) == 0:
raise ValueError('Error: unbalanced parentheses!')
stack[-1].children.append(node)
elif token in ('AND', 'OR'):
# In the event the top node uses the same conjunction, just
# continue on. Otherwise push a new node onto the stack.
if stack[-1].text != token:
top = stack.pop()
node = node_map[token](token)
if top.text == '' and len(top.children) == 1:
node.children.extend(top.children)
else:
node.children.append(top)
stack.append(node)
else:
node = Node(token.strip('"').lower())
stack[-1].children.append(node)
if len(stack) != 1:
raise ValueError('Error: unbalanced parentheses!')
return stack[0]
If you try this out in the console, you'll get a nice representation of the search terms:
>>> search_term = SearchTerm(phrase='peewee AND (python OR orm)')
>>> search_term.parse()
AND(peewee OR(python orm))
Compiling the search query
Now that we have a query tree, we need to compile it into executable Python code. I struggled with this for a bit, but then I settled on what I hope is a fairly idiomatic implementation -- I just added a code() method to the Node classes which is responsible for recursively generating the list of query conditions.
For text nodes, the question is simply "Does the given title contain the phrase we're interested in?". For AND and OR, we just need to know whether all or any of the child nodes meet their conditions, respectively.
Here are the updated implementations of the Node classes, which now contain a code() method:
class Node(object):
def __init__(self, text=''):
self.text = text
self.children = []
def __repr__(self):
if not self.children:
return self.text
else:
return '%s(%s)' % (
self.text,
' '.join(str(node) for node in self.children))
def code(self):
if self.text.startswith('-'):
return lambda s: self.text[1:] not in s
else:
return lambda s: self.text in s
class AndNode(Node):
def code(self):
def fn(s):
return all([
child.code()(s)
for child in self.children])
return fn
class OrNode(Node):
def code(self):
def fn(s):
return any([
child.code()(s)
for child in self.children])
return fn
Now that we have a way of converting the query tree into python code, we can fill in the SearchTerm.test() method, which will test whether the title matches the specified SearchTerm.phrase:
class SearchTerm(BaseModel):
# yadda yadda...
def parse(self):
# ...
return stack[0]
def test(self, s):
# Parse the search phrase into a `Node` tree, then generate a python
# function corresponding to the query conditions. Finally, apply that
# function to the incoming string, `s`.
return self.parse().code()(s)
Here's how to test strings against our search terms to see whether they match. Let's check it out in the interactive interpreter:
>>> from playground.models import *
>>> st = SearchTerm(phrase='peewee AND (python OR orm)')
>>> st.test('peewee')
False
>>> st.test('peewee is written with python')
True
>>> st.test('an orm named peewee')
True
>>> st.test('an orm written with python')
False
Extracting links from websites
The final piece is the code that extracts links from websites. This code needs to retrieve a list of links (consisting of a title and URL) from a specified URL. The catch is that some sites use RSS, some use a REST API, and in the future I may even want to scrape HTML, so the implementation needed to be flexible enough to handle all cases.
As I mentioned, the code will be extracting Link objects. Links are really just a title and a URL, so I've implemented them using namedtuple:
Link = namedtuple('Link', ('title', 'url'))
I then created a Searcher class which has a single abstract method extract_links. There are also helper methods for fetching content using HTTP and then testing the link using the SearchTerm model.
import urllib2
class Searcher(object):
user_agent = 'SaturdayMorningHacks/0.1'
def __init__(self, url):
self.url = url
def fetch(self):
request = urllib2.Request(self.url)
request.add_header('User-Agent', self.user_agent)
return urllib2.urlopen(request).read()
def search(self, search_terms):
content = self.fetch()
for link in self.extract_links(content):
for search_term in search_terms:
if search_term.test(link.title.lower()):
yield link
break
def extract_links(self, content):
raise NotImplementedError
I needed two implementations of Searcher, one for searching RSS feeds, the other for accessing Reddit's API. While Reddit does have RSS feeds, the links just take you to the comments page for the post, so I opted to use their API which exposes the actual content URL. For simplicity, I used the standard library ElementTree to parse the RSS.
import json
from xml.etree import ElementTree as etree
class FeedSearcher(Searcher):
def extract_links(self, content):
tree = etree.fromstring(content)
articles = tree.findall('channel/item')
for article in articles:
yield Link(
title=article.findtext('title'),
url=article.findtext('link'))
class RedditSearcher(Searcher):
def extract_links(self, content):
content = json.loads(content)
links = content['data']['children']
for link in links:
link_data = link['data']
if link_data['selftext'] == '':
yield Link(
title=link_data['title'],
url=link_data['url'])
Now that I have my Searcher implementations, I can create a list containing searchers for the sites I am interested in:
SEARCHERS = [
FeedSearcher('https://news.ycombinator.com/rss'),
RedditSearcher('http://www.reddit.com/r/programming/hot.json'),
RedditSearcher('http://www.reddit.com/r/Python/hot.json'),
]
Tying up loose ends
Lastly we need to set up a huey task to fetch the list of articles and generate an email digest. Huey is a multi-threaded task queue that plays nicely with Redis, but if you're just experimenting you can use the SQLite backend (or just run a script as a cronjob).
@huey.periodic_task(crontab(minute='0', hour='0'))
def content_search():
logger = app.logger
query = SearchTerm.select()
links = []
for searcher in SEARCHERS:
try:
results = searcher.search(query)
except:
logger.exception('Error fetching %s', searcher.url)
else:
for result in results:
exists = (SavedLink.select()
.where(SavedLink.url == result.url).exists())
if not exists:
SavedLink.create(title=link.title, url=link.url)
links.append(result)
if links:
digest = '\n'.join(
'"%s" -> %s' % (link.title, link.url)
for link in links)
send_email(my_email_address, 'Article digest', digest)
And that's all there is to it! While testing I got my first issue of my new Article digest and was very pleased with the results.
Thanks for reading
Thanks for reading this post, I hope you found it interesting. I had a lot of fun working on this project and am looking forward to tweaking my SearchTerms to achieve a really great stream of new content. Look for more posts in the future tagged saturday-morning-hacks -- I'm really liking this format.
If you're interested in more projects like this, check out the saturday-morning hack posts.
Comments (3)
Charles Leifer | may 11 2014, at 09:59pm
Thanks! I've integrated these features into a personal playground site (here's a post about it), which is set up to be deployed with fabric. I'm running on AWS, so I just have fabric commands to pull down the code, update pip requirements, and restart the server and task queue processes (which I manage with supervisor).
Ben Hughes | may 11 2014, at 06:01am
Love this series Charles - on this, what tools (if any) do you use to run/deploy these quick tools onto a server?
Commenting has been closed.
Mike | may 12 2014, at 09:02am
Just wanted to say that I've really been enjoying this series. Great post, looking forward to the next one!