Multi-threaded SQLite without the OperationalErrors
![]()
SQLite's write lock and pysqlite's clunky transaction state-machine are a toxic combination for multi-threaded applications. Unless you are very diligent about keeping your write transactions as short as possible, you can easily wind up with one thread accidentally holding a write transaction open for an unnecessarily long time. Threads that are waiting to write will then have a much greater likelihood of timing out while waiting for the lock, giving the illusion of poor performance.
In this post I'd like to share a very effective technique for performing writes to a SQLite database from multiple threads.
Overview
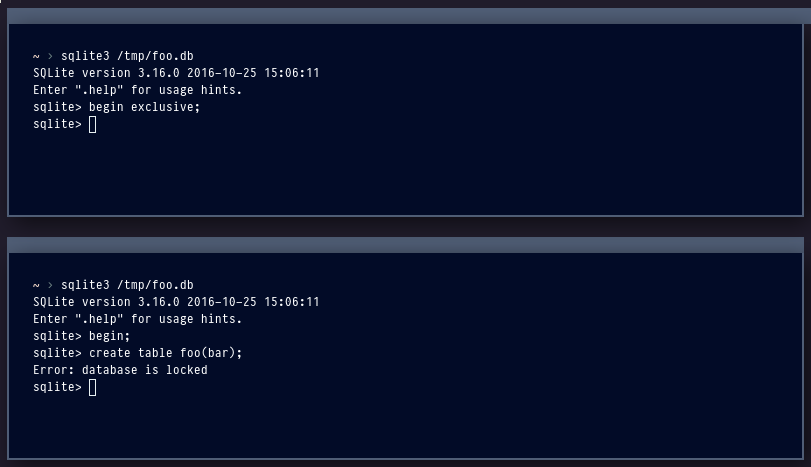
SQLite locks the database whenever a write transaction begins. Until that transaction commits or is rolled back, no other connection can write to the database (in older versions of SQLite, it used to be the case that readers were blocked, too, but thanks to the addition of write-ahead logging, readers can co-exist with the writer and vice-versa). Because SQLite does not allow two connections to write to the database simultaneously, SQLite is unsuitable for the entire class of applications that may require concurrent write access.
What I'd like to show in this post is that, although SQLite does not support multiple connections writing simultaneously, writes happen so quickly that it may be sufficient to merely provide the appearance of allowing concurrent writes.
For Python programmers, this situation is complicated by the convoluted transaction management of the standard library SQLite driver, pysqlite. By default, pysqlite opens a transaction when you issue your first write query (it does this by parsing every query you execute), and then committing that transaction when you issue any other query that is not a SELECT, INSERT, UPDATE or DELETE, e.g. CREATE TABLE or PRAGMA. This makes it very easy to issue a write, which acquires the write lock, and then keep that lock while you issue SELECT queries, etc, that have no need of the write lock, tying up the database for an unnecessarily long time.
Even if you manage to keep your write transactions very short, or even if you are running in autocommit mode, heavy contention for the write lock will inevitably lead to these:
OperationalError: database is locked
To see this for yourself, try the following:
Solving the problem by removing the problem
I've had success using a very simple approach: I eliminate the possibility of lock contention by dedicat ing one thread to the task of issuing all writes for the application.
Last Fall, I added a new extension module to Peewee ORM
called the SqliteQueueDatabase (documentation link)
that serializes all writes by pushing them to a dedicated writer thread. Best
of all, the SqliteQueueDatabase uses the same APIs as all other Peewee
databases and works as a drop-in replacement for the regular SqliteDatabase!
The implementation of SqliteQueueDatabase
Ordinarily, all queries get executed via the Database.execute_sql() method, and after execution will return a Cursor instance. Depending on the type of query executed, the Cursor can be used to retrieve result rows, fetch the number of rows modified, or get the last insert ID. Ordinarily this all happens synchronously.
With the addition of a separate thread handling writes, the query's actual execution becomes decoupled from the method-call that invokes it. It becomes asynchronous, in other words. To preserve the semantics of the original method call, I needed to:
- Block the caller if they ask for results from the query.
- Unblock the caller once the results are ready and communicate those results from the writer to the caller.
By doing the above, it appears to the caller as if the query were being executed synchronously.
The object responsible for retrieving results from a query is called a
Cursor. Peewee is designed to work with drivers that implement the
DB-API 2.0 spec, so under normal circumstances executing an INSERT query
looks like this:
- Get the current thread's connection to the database, creating the connection if one does not exist.
- Ask the connection to give us a cursor.
- Call
cursor.execute()to execute the query. - If we are in auto-commit mode (i.e. no transaction is active), call the
connection's
commit()method to sync the changes to the database. - Call the cursor's
lastrowid()method (or for Postgresql, which supports theRETURNINGclause, fetch the row containing the new ID) and return the new ID to the caller.
When using SqliteQueueDatabase, however, a separate thread is continually attempting to pull queries from it's work queue. When the worker gets a query to execute, it follows the usual pattern of obtaining a cursor from the connection and calling Cursor.execute(). Then, the worker notifies the caller that the query has been executed and results (if applicable) are ready.
We can use a threading primitive called an Event (docs) to notify the caller when results are ready. The Event object has a set() method, which is called by the writer thread when results are ready, and a corresponding wait() method which is used behind-the-scenes to block the caller while the query is in-flight.
To implement this, I created a simple class that exposes the same general interface as the usual DB-API 2.0 Cursor object. Here's a somewhat simplified version:
class AsyncCursor(object):
def __init__(self, event, sql, params, timeout):
self._event = event # Used to signal when results are ready.
self.sql = sql
self.params = params
self.timeout = timeout
self._cursor = None
self._rows = None
self._ready = False
def set_result(self, cursor):
# This method is called once the worker thread has executed the
# query (self.sql).
self._cursor = cursor
self._rows = cursor.fetchall()
self._event.set() # Wake up the thread that's waiting on the event.
return self
def _wait(self, timeout=None):
# This method is used by the caller to block until results are ready,
# or, optionally, raise an exception if the query takes longer than
# is acceptable.
timeout = timeout if timeout is not None else self.timeout
# Call the event's `wait()` method.
if not self._event.wait(timeout=timeout) and timeout:
raise ResultTimeout('results not ready, timed out.')
self._ready = True
def __iter__(self):
# If the caller attempts to iterate over the Cursor, first ensure
# that the results are ready before exposing a row iterator.
if not self._ready:
self._wait()
return iter(self._rows)
@property
def lastrowid(self):
# If the caller requests the ID of the most recently inserted row,
# we need to first make sure the query was actually executed.
if not self._ready:
self._wait()
return self._cursor.lastrowid
@property
def rowcount(self):
# Like lastrowid(), make sure the query was executed before returning
# the number of affected rows.
if not self._ready:
self._wait()
return self._cursor.rowcount
In the above code, AsyncCursor is really just a lazy result set, that only blocks when the caller requests information that could only be found by executing the query.
The writer thread handles all the work of executing the queries represented by AsyncCursor objects and calling set_result when a query is executed. The writer begins by opening a connection to the database, then waits for the database to send it write queries. When a write query is executed, the return object is the above AsyncCursor. A simplified version of the writer looks something like this:
class Writer(object):
def __init__(self, database, queue):
self.database = database
self.queue = queue
def run(self):
conn = self.database.get_conn()
while self.loop(conn):
pass
def loop(self, conn):
obj = self.queue.get()
if isinstance(obj, AsyncCursor):
self.execute(obj)
return True
elif obj is SHUTDOWN:
return False
def execute(self, async_cursor):
# Call the base-class implementation of execute_sql to avoid entering
# an endless chain of recursion.
db_cursor = SqliteExtDatabase.execute_sql(
self,
async_cursor.sql,
async_cursor.params)
return async_cursor.set_result(db_cursor)
The last piece is the integration with the Database.execute_sql() method, which is the API through which all queries are executed in Peewee. The only modification necessary is to check whether the query is a write query or not, and if so, place the query on the queue rather than executing it directly. The code looks something like this:
class SqliteQueueDatabase(SqliteExtDatabase):
def execute_sql(self, sql, params=None, require_commit=True, timeout=None):
if require_commit: # Treat this as a write query.
# Create an AsyncCursor object to encapsulate the execution
# of our write query, add it to the writer thread's queue, and
# return the wrapper to the caller.
async_cursor = AsyncCursor(
event=threading.Event(),
sql=sql,
params=params,
timeout=timeout)
self.write_queue.put(async_cursor)
return async_cursor
else: # Regular read query.
return super(SqliteQueueDatabase, self).execute_sql(
sql, params, require_commit)
The entire source listing can be found here, if you're curious: https://github.com/coleifer/peewee/blob/master/playhouse/sqliteq.py
In practice
I've found the approach outlined in this post to be very robust and performant. I've had it deployed in a couple web applications for several months now and haven't seen a single Database is locked issue. Best of all, in most cases I didn't have to change any application code - I could simply swap the database declaration.
There is one important gotcha to be aware of before using this in your own code: transactions will no longer behave as you might expect. Because all write queries are executed using the same connection, and because the write queries may arrive in the queue out-of-order (when multiple threads are issuing writes at the same time), it is impossible to predict how a multi-statement transaction would play out.
To mitigate this, I'm in the process of adding a Redis-like Pipeline API to the SqliteQueueDatabase which will ensure that a batch of writes executes sequentially, without any other writes interleaved. The code should be ready soon!
Parting shot
A lot of Python people have been burned by the bizarre transaction semantics enforced by pysqlite and, because of that, assume that SQLite must be to blame. In my experience, however, keeping write transactions short and explicit will mitigate almost all problems! For the times when you're still running into issues, I'd suggest trying an approach like the one described in this post.
Last, but not least, remember: nobody likes the fopen guy:
Comments (3)
Charles | feb 03 2017, at 09:08pm
Thanks for bringing up isolation levels, Grant. You are absolutely correct in that settings the isolation_level to None will remove all the bad magic, and you're running in autocommit mode. Behind-the-scenes, Peewee does just this whenever you use SQLite, since Peewee provides its own APIs for transaction management.
Grant Jenks | feb 02 2017, at 01:32pm
It's worth mentioning the "isolation_level" parameter to the "connect" initializer. Setting the isolation level to None will disable the transaction state machine wonkiness. The supposed drawback is a new transaction for every statement. But many people expect that behavior anyway. Transactions can still be used for multiple statements by explicitly beginning with rollback or commit. Coupled with Python's "with" statements and context managers for resource management, I have found explicit transaction management easier to implement and reason about. The Python DiskCache project does exactly this: http://www.grantjenks.com/docs/diskcache/
Commenting has been closed.
Leonardo | feb 04 2017, at 03:28am
I've had to fight with the OperationalError just a bunch of weeks ago. I have a multithreaded application in which i have to analyze several hundreds of thousand of entries retrieved from a mysql connection, process it and mark a bunch of flags inside a sqlite's database. Since i wanted to abstract myself from the database part, i opted for PonyORM, which sadly enough looks like is not capable of handling these kind of situations. In the end i discovered too late what was the problem, so i opted for a try/catch statement and a random incremental sleep for every critical section inside my code; the result is frustrating and in the long running does not solves anything. Infact, after 3 days of running, you can see how every thread is stopped waiting inside the critical section, and with enough threads running, the process continues its job for half an hour every 4 hours. So, i guess now i could give a try to peewee, hoping the transiction from PonyORM is easy.